LSM-Tree 缓解写放大 论文笔记
缓解 LSM-Tree write amplification / write stall 的论文列表:
(7 篇文章)
- bLSM: A General Purpose Log Structured Merge Tree(SIGMOD 2012)
第一次提出针对 Write Stall 的优化调度方法,提出弹簧-齿轮调度器;
核心思想是允许在每一层增加额外的调度控制组件来并发调度不同层的flush/compaction 过程;
- A Priority and Fairness Mixed Compaction Scheduling Mechanism for LSM-tree Based KV-Stores(ICA3PP 2018)体系结构会议
提出了新的压缩调度方案:将以分数为中心的优先级调度与以时间片为中心的公平性调度相结合,减少每层(each component)SST 文件的数量,进而减少写放大;
- LSM-based Storage Techniques: A Survey(VLDB Journel 2020)
总结了到 2019 年为止所有的 LSM-Tree 的优化方向和优化策略,其中在 write stall 方面对 blsm 进行了评价:设计上仅适用于未分区的分层合并策略,没有考虑更复杂的分区管理策略;仅优化了写入内存组件的最大延迟,而忽略了写入请求的排队延迟,这可能导致系统在高负载情况下性能不稳定。
bLSM is the only effort that attempts to address this problem(since 2019)
未分区的 lsm-tree 系统:leveldb、rocksdb
分区管理的 lsm-tree 系统:Cassandra、HBase
- MatrixKV: Reducing Write Stalls and Write Amplification in LSM-tree Based KV Stores with Matrix Container in NVM(ATC 2020)华科
首次提出将 L0 层数据放入 NVM,利用细粒度列压缩,减少树深度等方式降低 LSM-Tree 的写放大和写停滞;
- PM-Blade: A Persistent Memory Augmented LSM-tree Storage for Database(ICDE 2023)华东师大
用了PM+协程,优化的是压缩,减少写放大,但并没有针对 write stall 进行优化
解决方案:在基于 PM 的 L0 层进行内部压缩,将 L0 层转化为 sorted;
提出 cost-based compaction:基于代价的压缩策略提高读效率,减少写放大;
同时第一次提出基于协程的压缩方法,减少 CPU 等待时间和 IO 争用;
- On Performance Stability in LSM-based Storage Systems(VLDB 20)
一种两阶段实验方法评测 LSM-Tree 的 write stall 问题
对 write stall 的优化方法提出一些参考性建议
- A GPU-accelerated Compaction Strategy for LSM-based Key-Value Store System(MSST 2024)南开 体系结构会议
重点研究当 KV 对的大小为 中小型 时,利用 GPU 加速合并;
提出两种 NVMe SSD + GPU 数据传输机制:pipeline、P2P,最小化压缩过程的数据传输开销;
基于 Leveldb 实现,能够尽可能减少 write stall,使吞吐量趋于稳定;
bLSM: A General Purpose Log Structured Merge Tree
论文重点概述:
1、每层数据 compaction 的代价计算:
完整数据总量:
代价总和:total cost =
现在目标是让代价总和最小,即最优化问题
由拉格朗日:
即求偏导:
得到只有
带回得到:两层之间最佳的比率为
但由于实际情况下要插入的数据总量
最小化总的压缩代价,只能减少写放大,但对 write stall 没有很好的效果;
2、分区调度器与层调度器对比
分区调度器 Partition schedulers 在特定倾斜分布的负载场景下能尽可能减少 IO,减少写停滞,如 Cassandra、HBase 系统应用了这个优化,但缺点也很明显,当数据分布不倾斜时,这种调度方案没有显著效果,因此 leveldb、rocksdb 没有采用,作者接下来提出为不分区的 LSM-Tree 系统的层调度器方案(spring-and-gear scheduler)
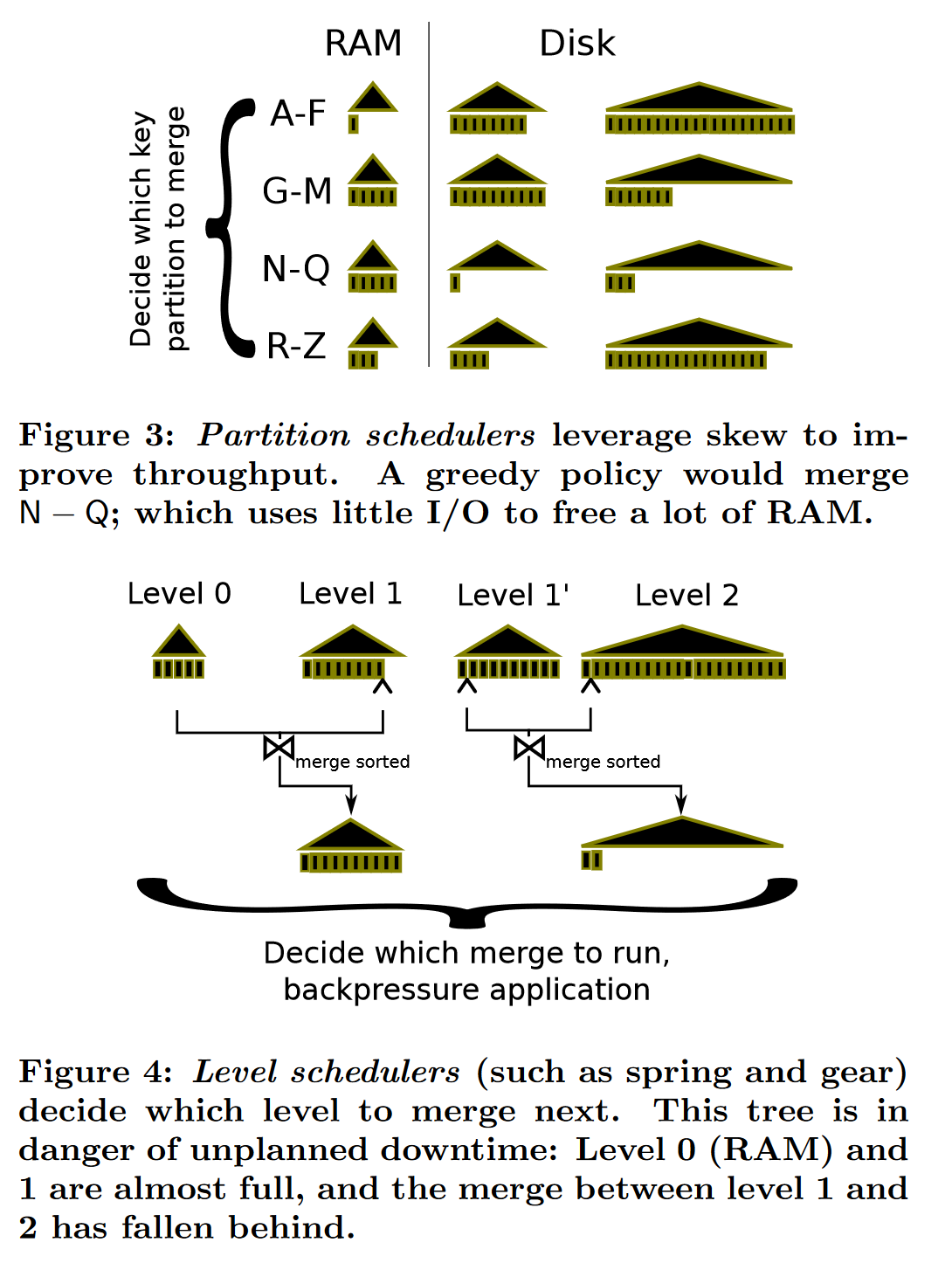
3、弹簧-齿轮调度器的设计
3.1 首先是作者最初的想法:齿轮调度器的建模
核心思想:
每层合并过程维护两个进度指示器,来控制合并线程的执行;
只要上下游合并能够保持一个相对的进度,write stall 问题就会尽可能避免发生
(相对进度可以形象理解为多个齿轮之间的啮合运转,不会说某一层合并过慢导致前台停止接收写请求)
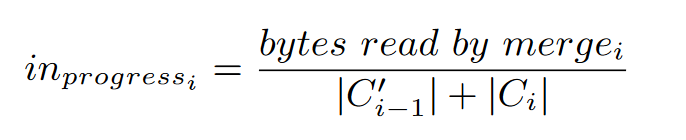
入合并操作的进度:分子为当前层的合并已读取的字节数
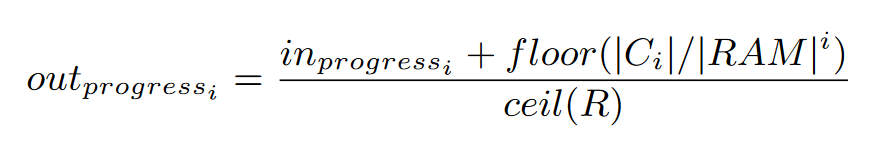
出合并操作的进度:
根据这两个进度指示器:要么减少上层写吞吐、要么停止合并让出CPU资源
就比如现在数据积压特别多,那就让给压缩线程,减少上层写吞吐,不至于整个系统直接 write stall
3.2 其次,在压缩合并过程中,比如 L0~L1,涉及到外排,作者提到外排用的是替换选择外排(扫雪机模型),而不是传统的多路归并外排;
优点是:替换选择外排优化的是外排的分割阶段,尽可能让分割后的每个顺串(SST file) 长度最大化;
从而减少初始读写 I/O,并且用小根堆实现,能够与最终提出的水位线方法相契合;
3.3 弹簧-齿轮调度器
为什么需要改进:齿轮调度器太脆弱,合并与插入操作绑定得太紧,同时与外排铲雪机模型交互性太差;
改进方法:在齿轮调度器的基础上,施加 low,high 水位线,比如:L0快满时反向施压,系统内部降低对写请求的接收频率,L0快空时尽量减少合并,停止压缩线程,让出 CPU 资源,给前台接收用户的写请求。
本质:控制合并的速率,在线程级别上进行调度的调控
性能表现:
OPS 在 2W 左右
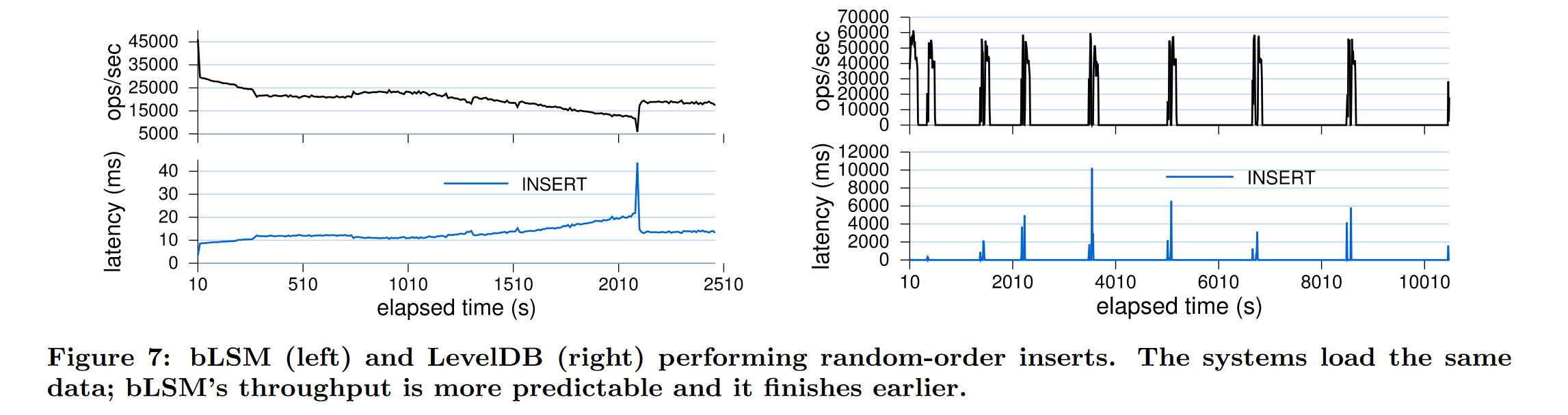
本篇文章复现的缺点:
虽然论文中给出了 github 代码地址,但由于长期不维护并且是基于06年伯克利的一个系统的优化型插件,跑不出来,19年有人提 issue 但都没人理,如果往后做对比实验可能只能照着论文思路自己实现个简单的版本。
MatrixKV: Reducing Write Stalls and Write Amplification in LSM-tree Based KV Stores with Matrix Container in NVM
论文主要贡献点:
1、关于 write stall,写放大等原因与来源分析:
- 主要来源于 L0 ~ L1 的压缩合并
- 写放大随着 LSM-Tree 深度的增加而增加
LSM-Tree 的 immemtable 是跳表结构,整体有序,每当跳表满了就直接刷入磁盘上的 L0 层:
也就是说,L0 层多个 SST File 之间是无序的,SST 内部是有序的;
而 L1~Ln SST File 整体是完全有序的;
正因为 L0 可能存在多个 SST File 有针对相同 key 的增删改操作,每次合并几乎都是全量 merge;
而 L1~Ln merge 只需根据 key 的范围,选边界相同的几个 SST File 进行合并,I/O少很多。
2、提出的几个贡献点:
- 将 L0 层所有数据放入 PM
- 对 L0 层进行细粒度列压缩策略,减少 write stall
- 减少 level 数量方式减少写放大
- Cross-Row hint search 方法提高读性能
3、具体实现
对于 L0 层,每行 RowTable 存储 immemtable 一次性 flush 的数据,即每行数据有序,可理解为每行就是原先的一个 SST File;
内部压缩阶段,进行一个分区合并处理,按照 key 范围分区,多个行合并成一个大的行;
之后按照分区重新组成一个个 SST File
本质思想:让原本无序的 L0 层在 PM 快速存取特性下变成多个完全有序的 SST,进而让 L0 到 L1 的合并尽可能减少 I/O;

4、论文的实现效果
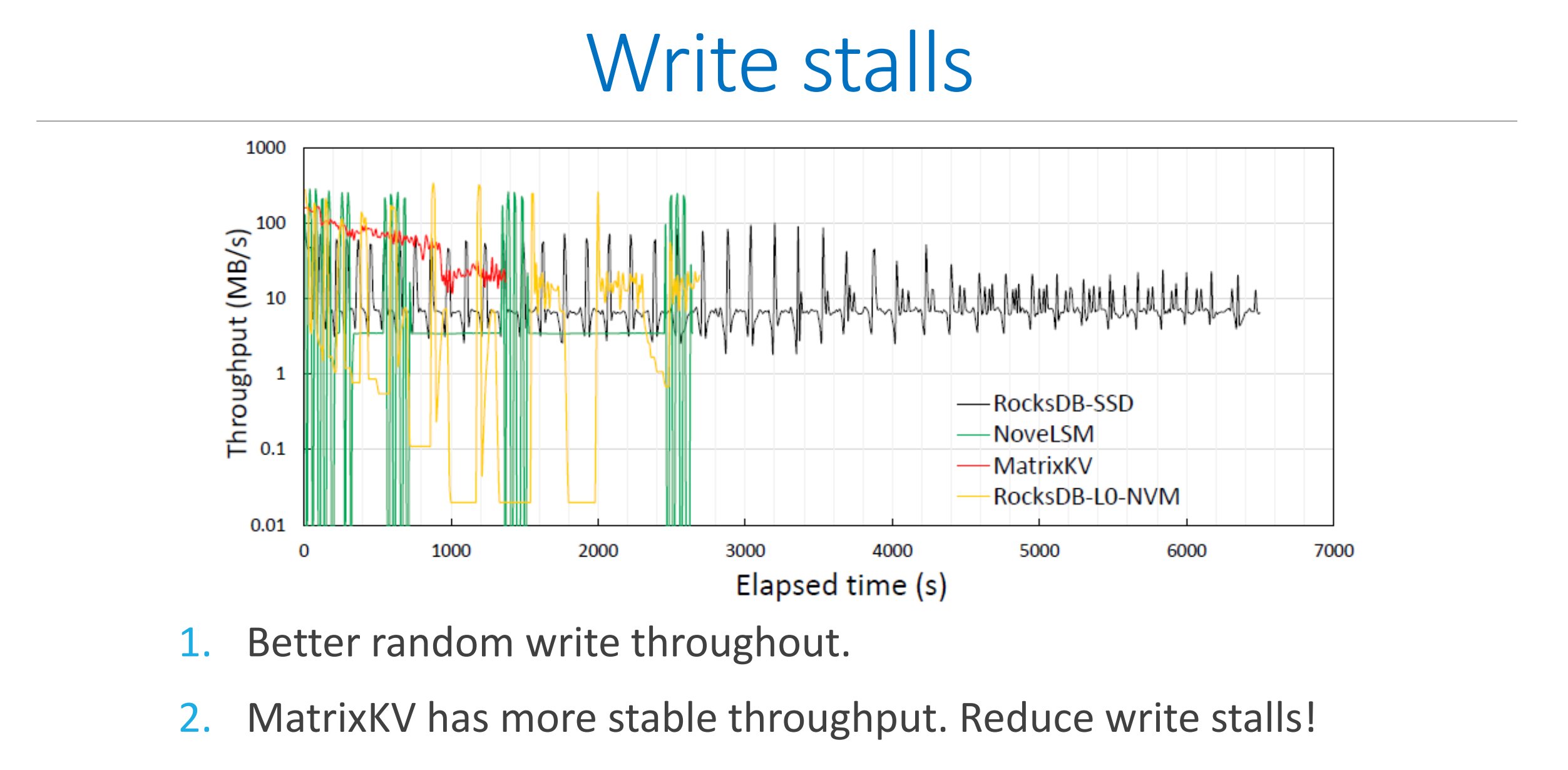
PM-Blade: A Persistent Memory Augmented LSM-tree Storage for Database
PM-Blade 贡献点
- 利用 PM 优化读性能,同时减少写放大;
- 在基于 PM 的 L0 层进行内部压缩,将 L0 层转化为 sorted;
- 提出 cost-based compaction:在 L0 层基于代价的压缩策略提高读效率,减少写放大;
- 第一次提出在 LSM-Tree 中使用基于协程的压缩方法,减少 CPU 等待时间和 IO 争用;
1、整体架构
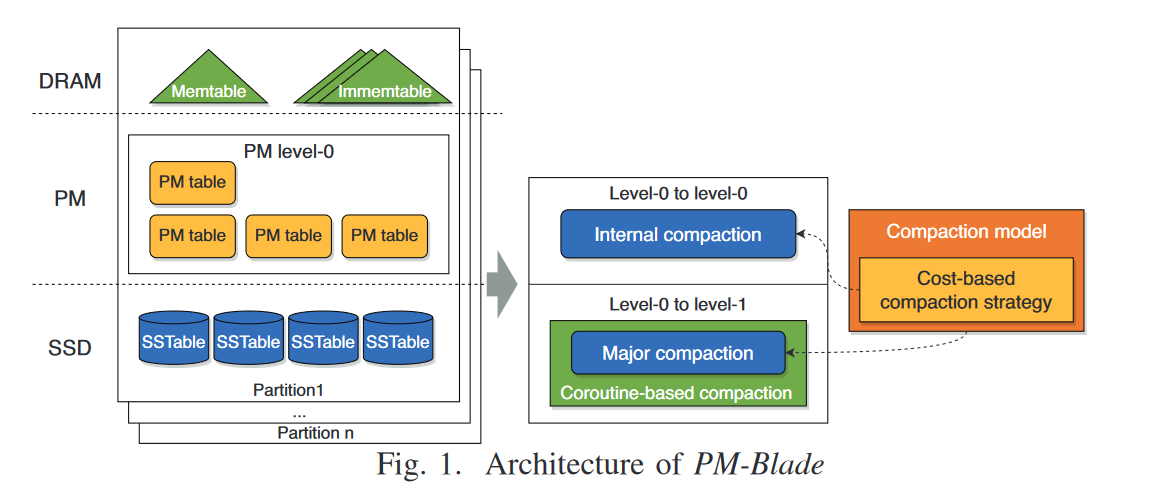
2、L0层的数据存储格式
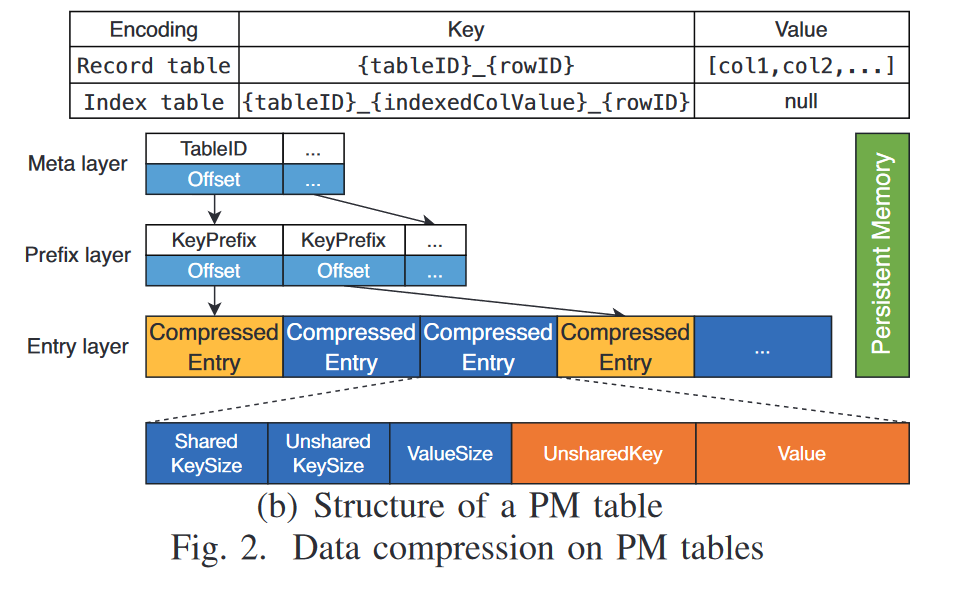
每个压缩后的键值对存储为:[共享键长度,额外长度,值大小,额外键,具体值]
Example:[ {apple, 10}, {applet, 20}, {application, 30} ]
After store:[ [0, 5, 2, ‘apple’, ‘10’], [5, 1, 2, ‘t’, ‘20’], [4, 7, 2, ‘ication’, ‘30’] ]
3、L0 层的 Internel compaction
unsorted tables:由 immemtable 直接 flush 下来的,每个块内部有序;
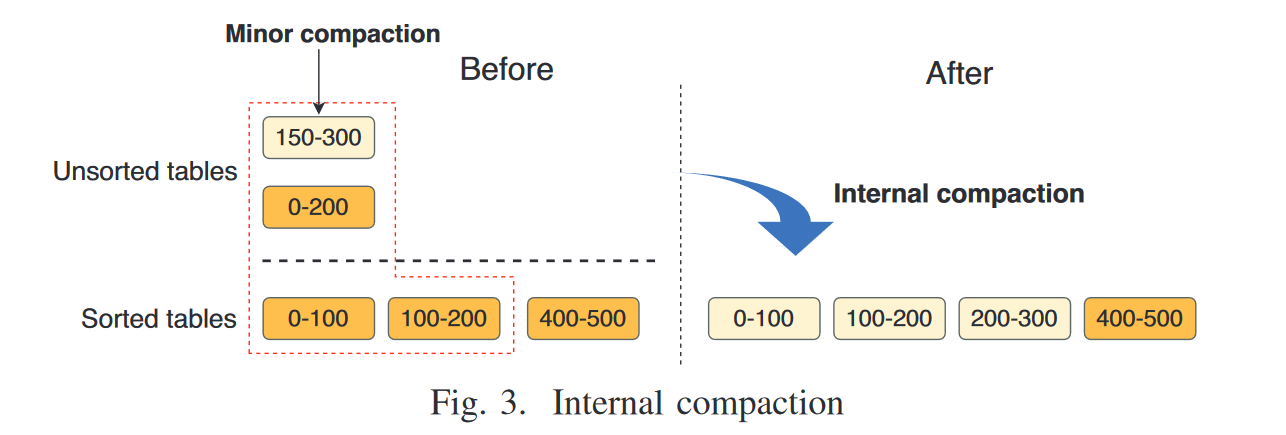
4、压缩模型 compaction model 指导压缩线程的调度
压缩模型的三个目标:
- 随着 L0 层 PM table 的增加,缓解读放大的问题
- 充分利用 PM 空间,减少下层合并的写放大问题
- 尽可能让 warm 数据留在 L0 层的 PM table,减少读数据的访问 IO
算法1:给出了压缩策略的调度流程

1、当一个新的 PM 表被刷新到 L0 时,用公式1 rf 读放大的代价来判定是否使用内部压缩对读操作进行加速
2、判断
3、最后判断整个 L0 层的容量是否超过阈值
符号解释:
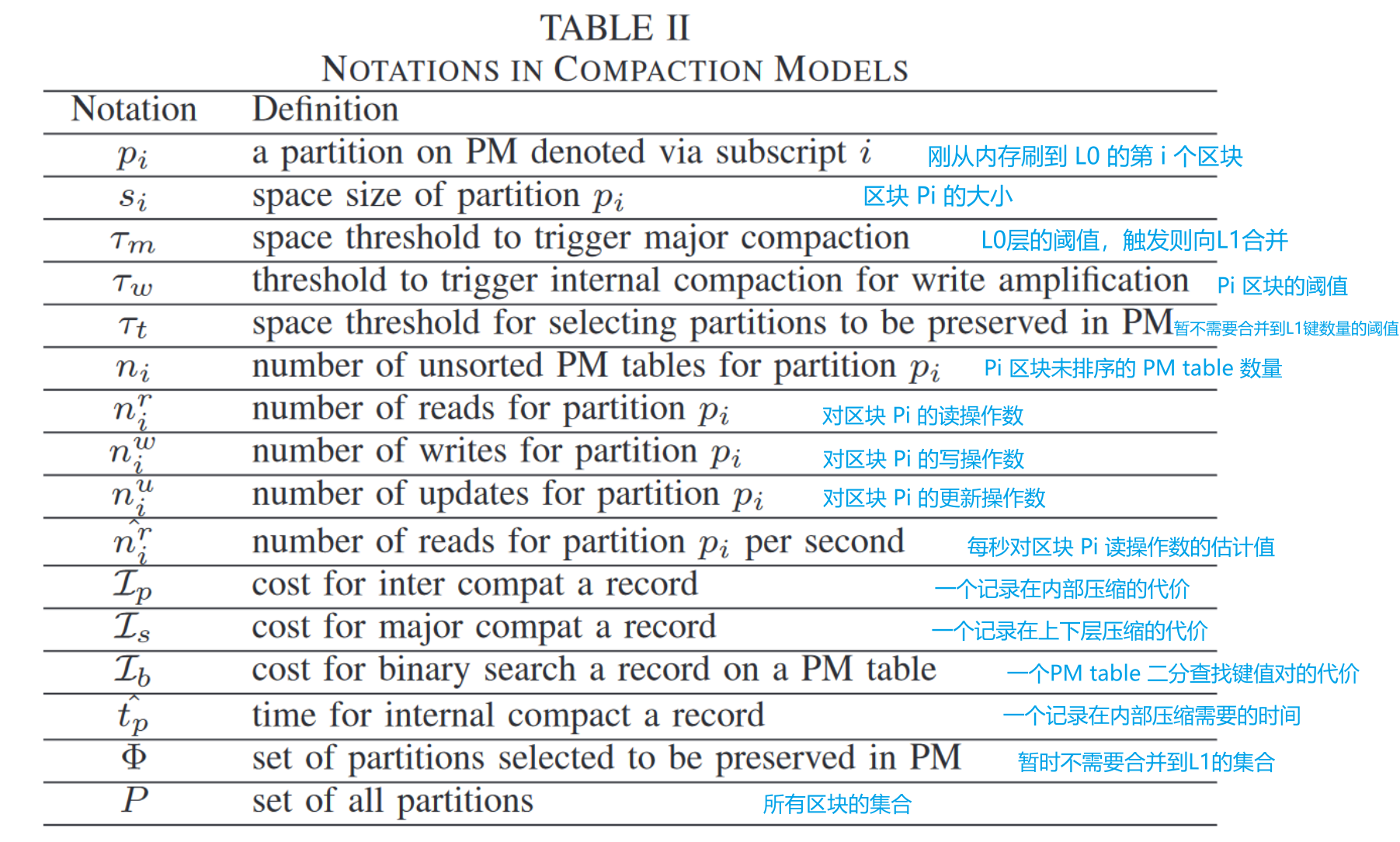
公式1理解
内部压缩能够提高读性能,但在不恰当的时间段进行内部压缩会产生过多的额外开销,比如当一个区块 partition 只包含少量 unsorted table 并且读的很少,对这个区块进行内部压缩是不需要的。
推导:读数据代价 = 压缩前读的代价 - 压缩后读的代价 - 压缩过程在单位时间内的成本代价
压缩前存在
压缩后,仅需1个,
因此,
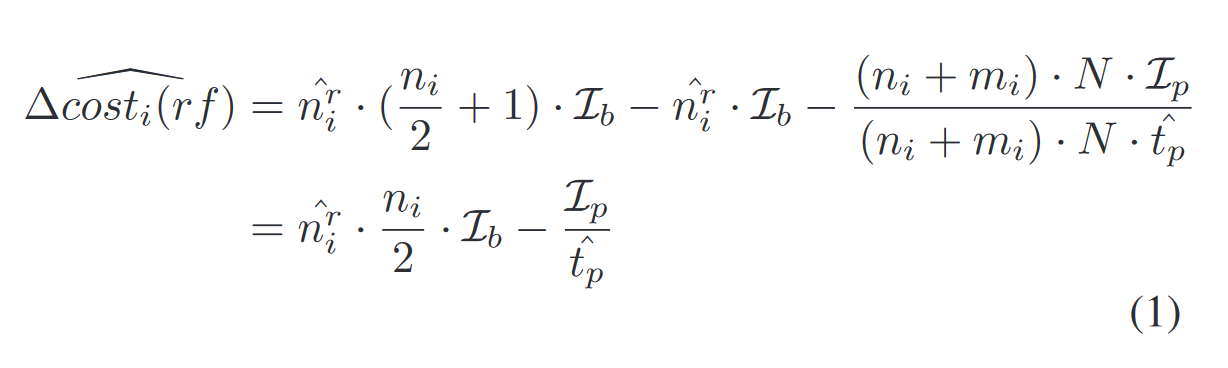
公式2:尽可能减少写放大
当区块
若
意味着 内部压缩消失的数据若直接参与下层的合并代价 高于 压缩前所有数据参与内部压缩的代价,此时,内部压缩比直接进行下层合并要划算得多,进而减少写放大。
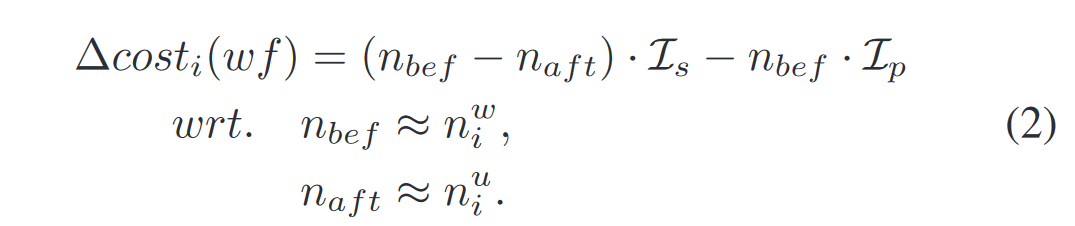
公式3:尽可能将 warm 数据留在 L0 层
由于 L0 各个 SST File 之间在内部压缩后形成有序,向下层合并过程不需要所有 SST File 参与;
我们可以决定哪些 SST File 需要合并到 L1
公式 3 将它抽象成一个背包问题,选取哪几个 SST File 合并能够让效益最大化
即选取的几个分区,它们受到用户侧读取的数据频率最多,这几个分区可以留在 L0 层,
同时它们的累加大小总和小于暂不向下合并的阈值
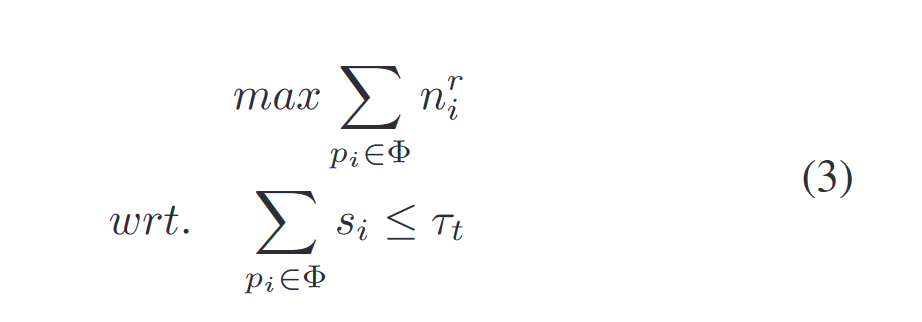
以上就是 cost-based compaction model
5、基于协程的压缩方法
以下的压缩仅用于 major compaction:上下层之间的压缩
表3是在单核 CPU 上运行多个 compaction 任务,每个任务由一个线程负责,即使如此,无论是 CPU 还是 IO 设备,都没有充分利用好,大部分时间都处在空闲。
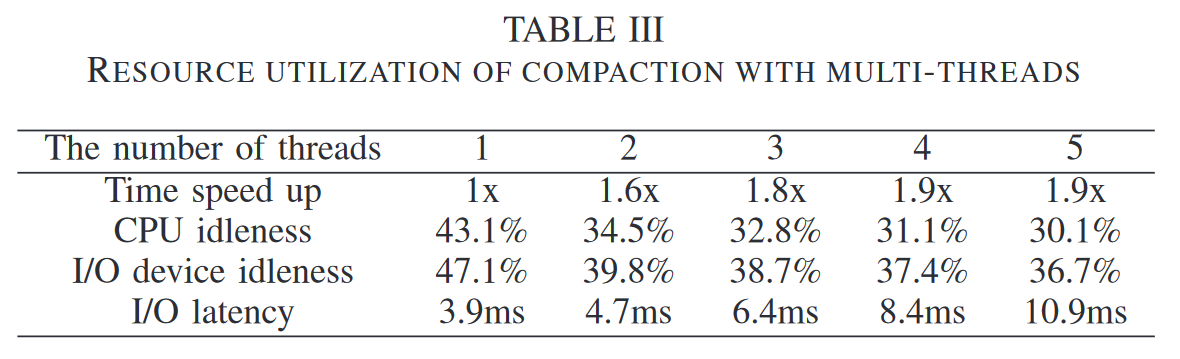
合并过程可以分为三个阶段:
- read block:将
层数据读入内存 read buffer - sort:在 read buffer 中排好序,并放入内存中另外一个区域 write buffer
- write block:一旦 write buffer 填充满了,立刻刷盘
S1, S3 都是 IO 操作,S2 为 CPU 操作,因此一个理想的合并过程应该是图4(a)
但在实际测试中发现,图4(b) 才是一般情况,即出现极短的 S2 ( fragment time )
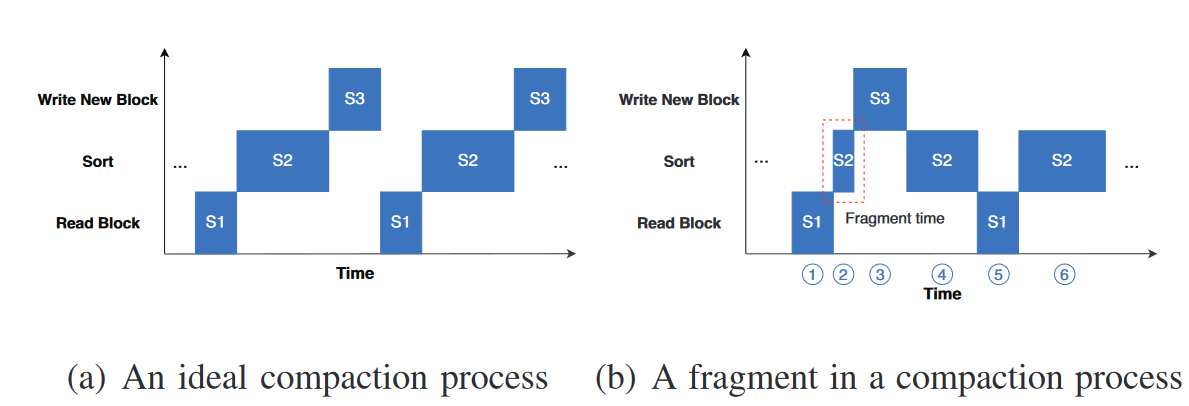
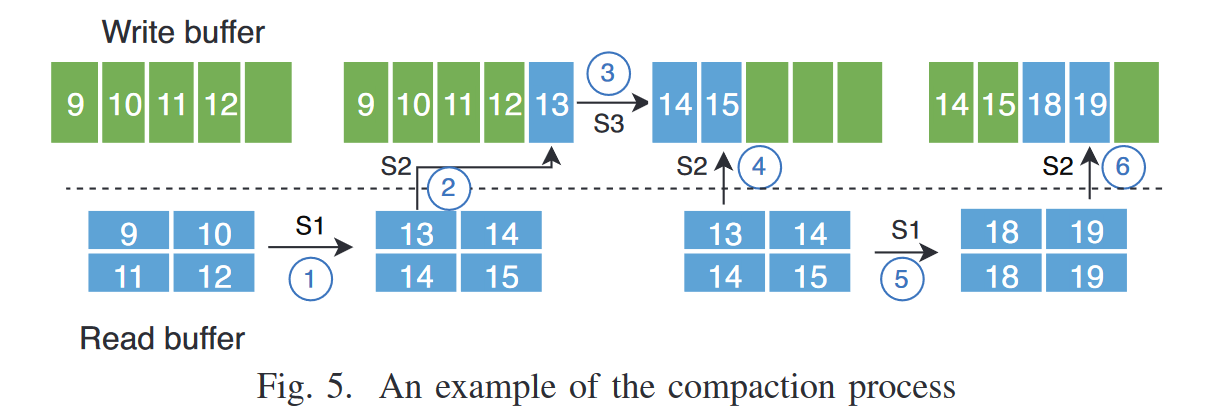
产生的原因本质上是内存缓冲区的大小是有限的,因此转移缓冲区操作会产生碎片时间,以图5为例
第一个 S2 将 13 放入 write buffer 后,缓冲区满了,立刻执行 S3 刷入磁盘,而此时 read buffer 并不算太空,没有必要执行 read buffer 这个 IO 操作,因此 S3 结束后,依然是 S2,全部转移走后才执行S1读取数据
针对这个实际情况,如果直接上协程,即每个协程分配一个压缩操作,会无法充分利用 CPU 和 IO
图4(c) 的 CPU,IO 利用率分析,比如 S2 阶段切换任务后,C2协程一下就做完了,此时虽然 C1的S3 和 C2的S2 同时结束,但由于是随机性调度,调度给到 C2的S3 执行,导致让 CPU 处于闲置。
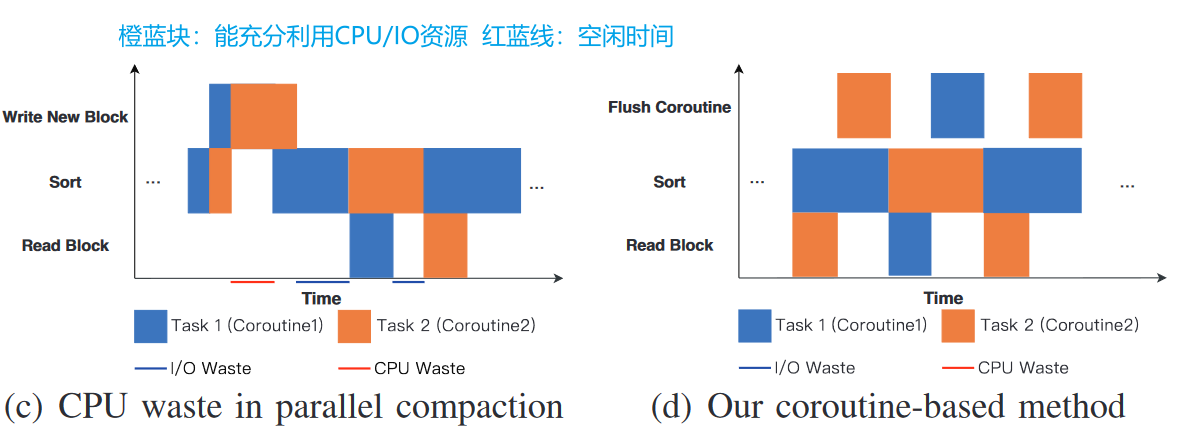
coroutine-based method
优化方面:
- 将 S2 产生的碎片时间消除
- 调度协程防止突发的 IO 争用
具体做法:
- 将 S3 阶段分配一个专用的 flush 协程
原先对 write buffer 的处理策略是只有缓冲池满了,立刻刷入磁盘,这就导致 S2 执行时 write buffer 可能已经存在部分数据,进而存在碎片时间
现在由一个专门的 flush coroutine 进行刷盘,无需等待缓冲池满了的情况
并且这个协程可以由接下来的协程调度器进行调度。
- 提出一个协程调度策略,并将一个完整的 compaction 任务划分为多个协程级子任务
调度器的核心思想:当IO压力较低时执行IO操作,并在压力变高时限制IO操作数量;
具体方法:对 IO 数量进行监控,建立 flush 协程数量的数学模型
q:系统最大值,一般由用户设定
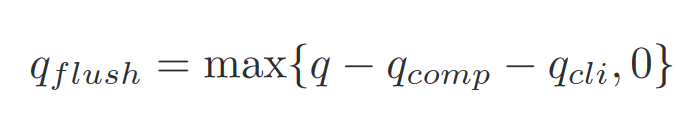
在实现上,关于线程绑定物理核:
To take full advantage of multicore, we assign c worker threads to c physical cores.
1 | |
论文实验结果
benchmark:db_bench, ycsb
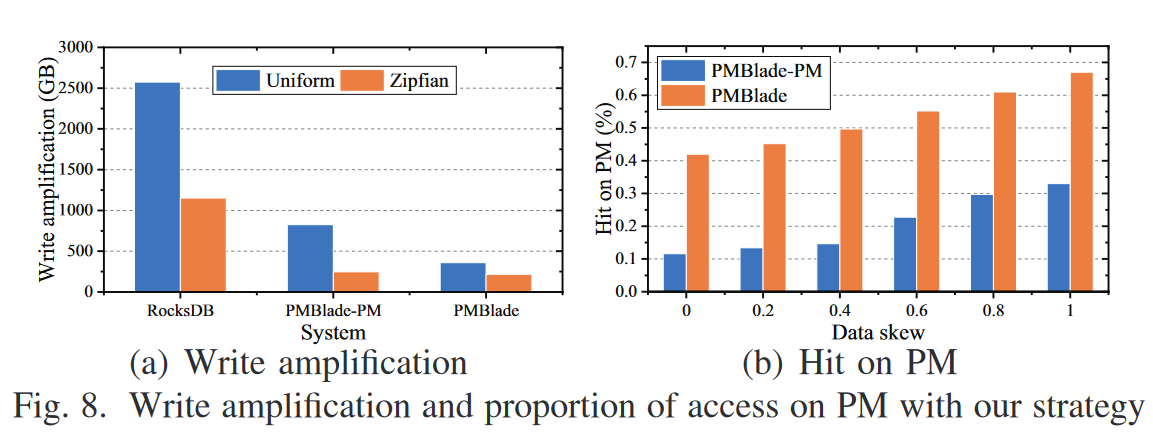
- 用了 PM 后,写放大显著降低
- PM 对比 SSD,在读延迟方面的降低
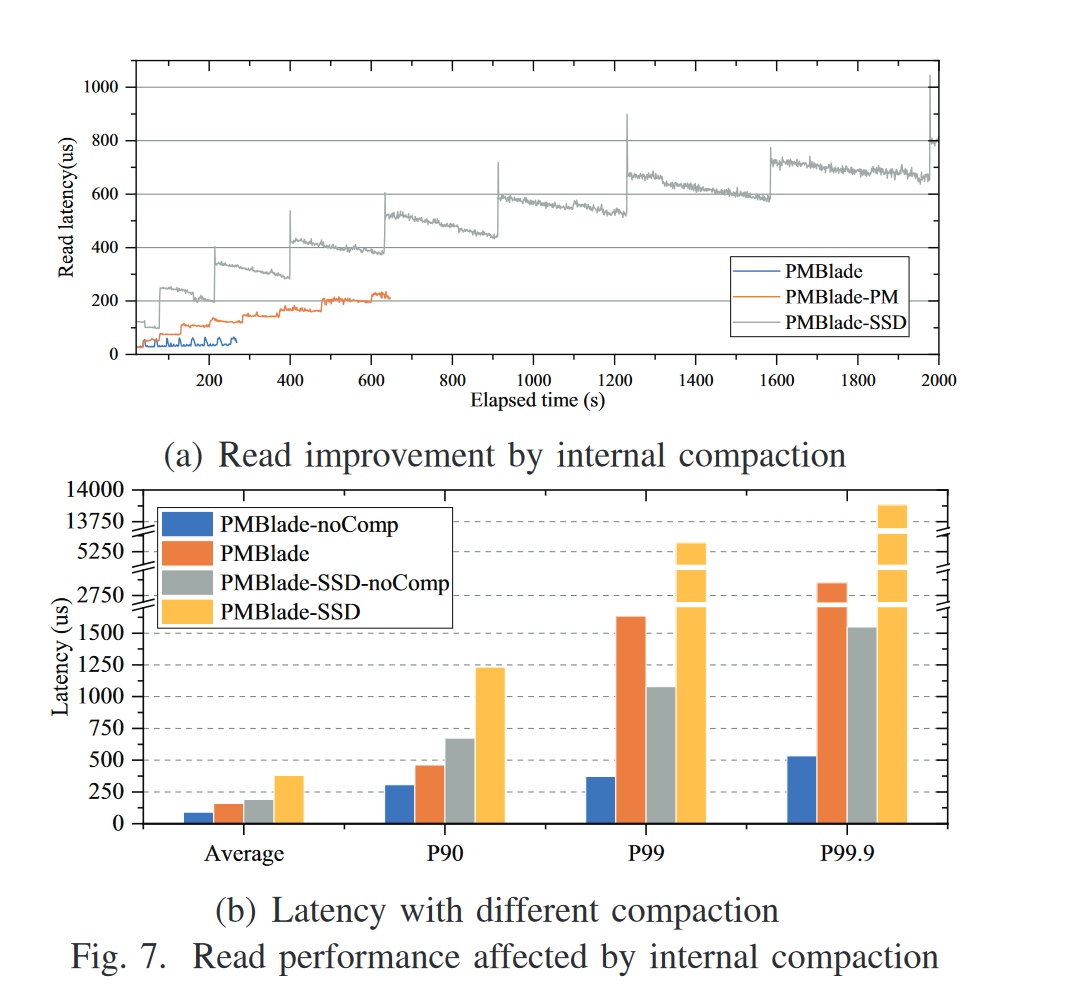
- 线程调度策略、朴素的协程调度策略、PMBlade调度策略对比

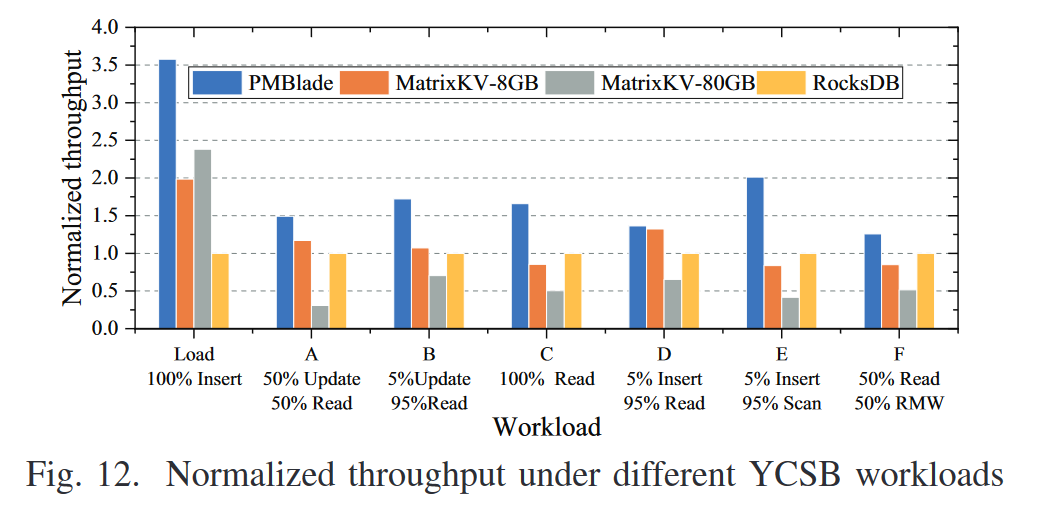
- ycsb不同负载下的多个系统间的吞吐对比
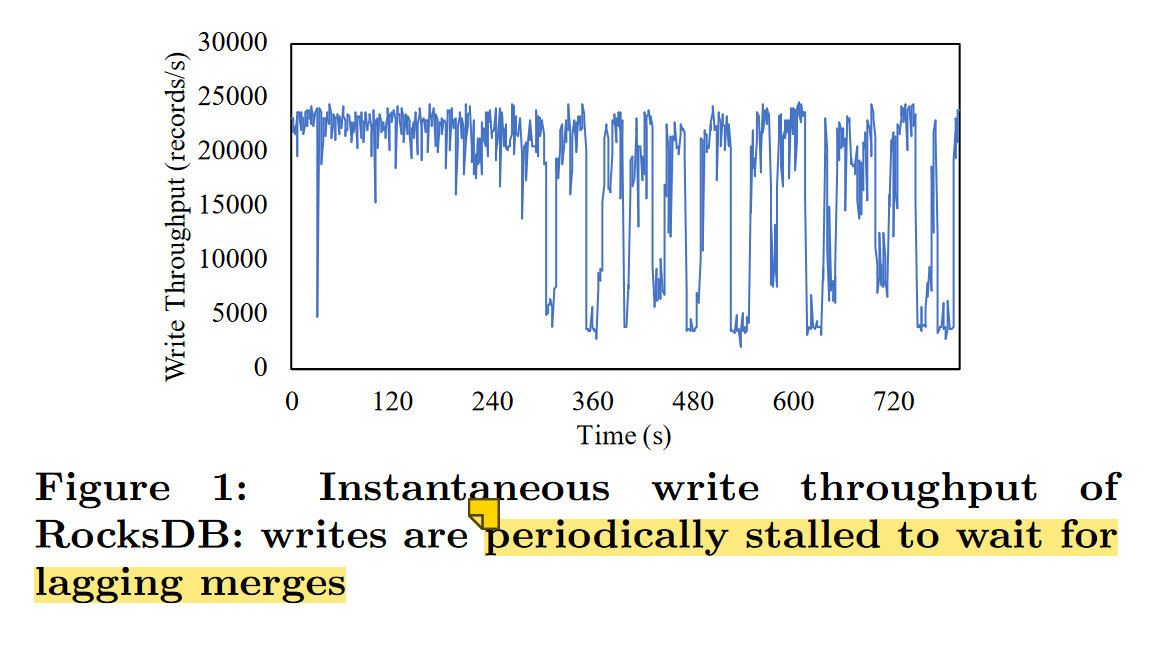
On Performance Stability in LSM-based Storage Systems
贡献点:
- 两阶段实验方法来评估各种 LSM-Tree 的写延迟
- 探索 LSM 合并调度器的设计
分析 write stall 出现的原因
- 快速的内存写操作和较慢的背景 IO 操作之间的不匹配,如果异步的 IO flush / merge 跟不上,前台的内存写操作就会减慢或停止;
- 数据到达率 data arrival rate 直接影响 LSM-Tree 的写延迟,如果数据到达率较低,写入停滞发生的可能就会更低
作者提出两个问题作为方向指导:
- 如果数据到达率为最大写吞吐的 95%,是否还会导致写停滞?
- LSM-Tree 是否能设计成高写吞吐、低写延迟?
两阶段评估:
- 测试阶段,尽可能多的写测量最大写吞吐
- 运行阶段,以接近实测最大写吞吐的数据达到率,评估写停滞
实现上面临的挑战:
- 如何准确测量出 LSM-Tree 的最大写入吞吐?
- 如何对 LSM-Tree 的 IO 操作进行最优调度,从而在运行时最小化写停滞?
实验结果:
LSM-Tree 的合并调度器的策略确实会对写停滞带来很大的影响
作者听出一种新的合并调度器来解决挑战
通过他们的方法和设置,LSM-Tree 能够同时保证较高的吞吐和较低的写停滞
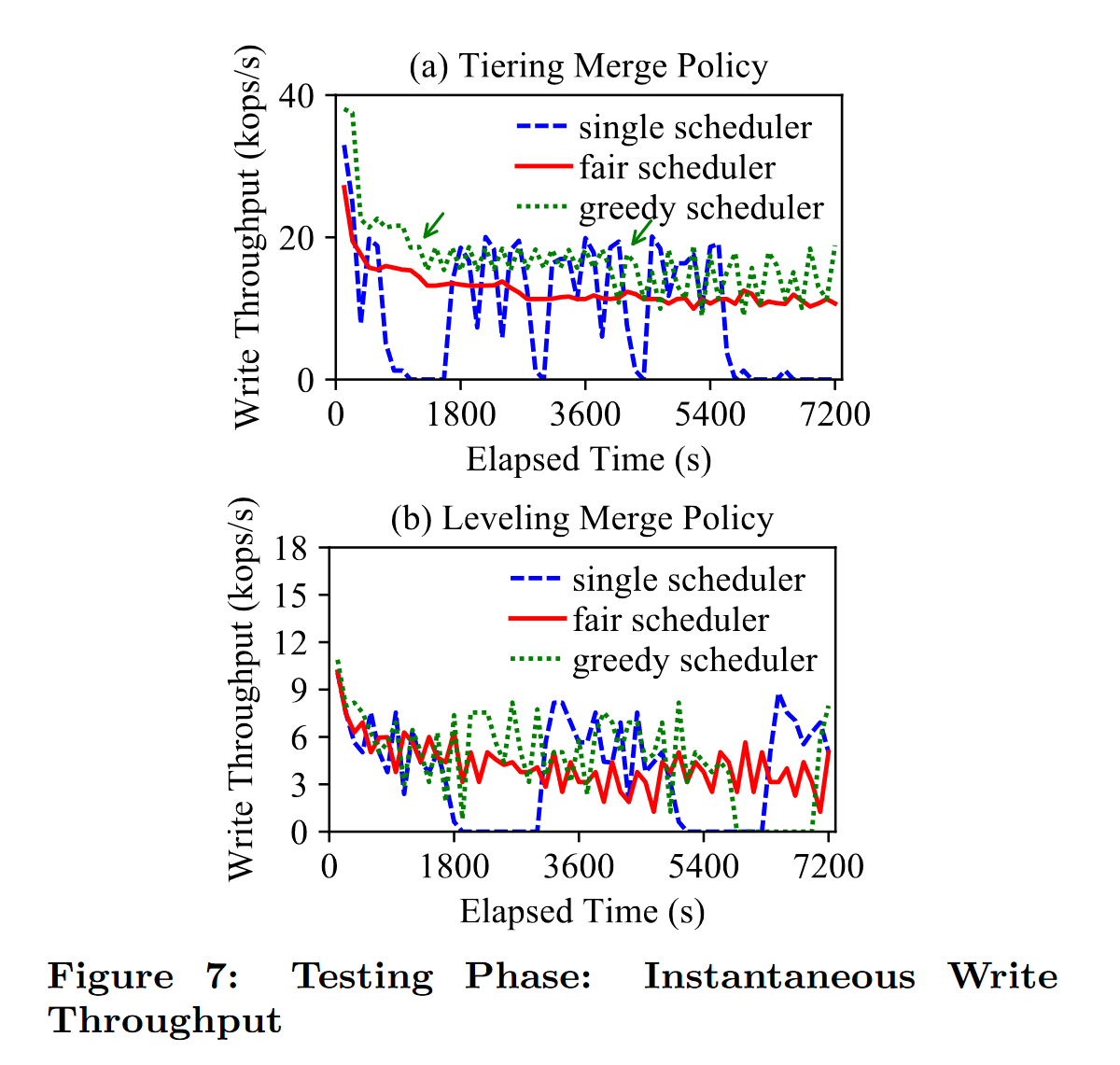
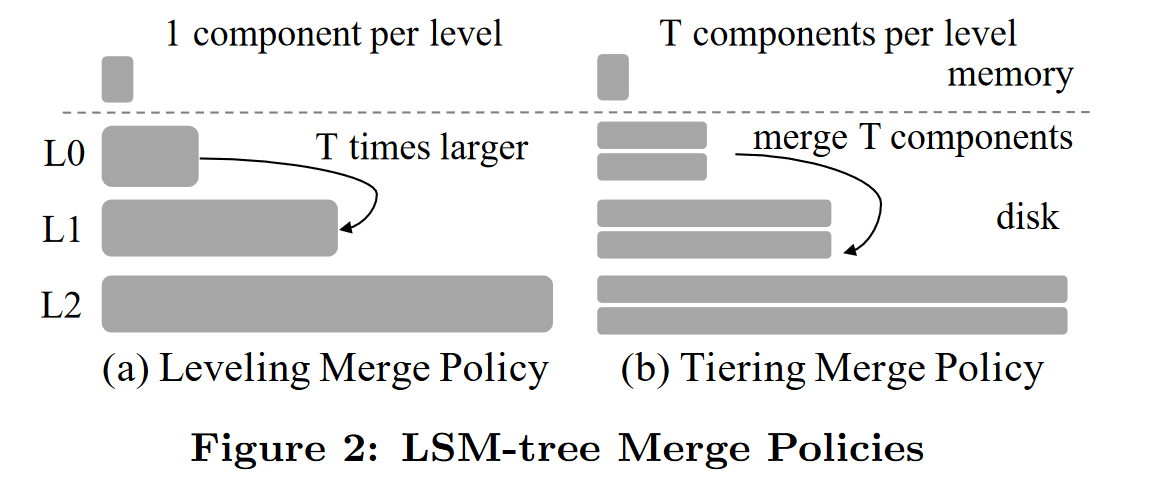
Merge Policy
- Leveling Merge Policy 分级合并(适用于读密集型)Leveldb
每一层的文件大小相对均匀,level i+1 比 level i 固定大 T 倍
减少读放大,查询快延迟低:每层文件大小均匀,需要访问的文件数少
空间利用率高
增加写放大:合并频繁,IO 写操作过多
- Tiering Merge Policy 分层合并(适用于写密集型)
每一层包含一组文件,当每层文件数或总大小达到阈值时,触发合并
高效写入:批量合并,降低前一种频繁合并的写放大
空间利用率低
增加读放大:读取操作需要扫描更多的文件
评测部分 性能度量的三个指标:
- Arrival Rate:客户端提交写操作的速率
- Processing Rate:LSM-Tree 可以处理写操作的速率
- Write Throughput:LSM-Tree 单位时间内处理的写次数
LSM-Tree 的写入代价
由LSM-Tree设计和工作负载决定,而不是由如何执行合并确定;
但不同的调度选择会影响 LSM-Tree 的写延迟,通过精心设计合并调度能最小化写延迟;
提出一种 greedy scheduler:
优先将 IO 带宽分配给当前 k 个最小的合并操作,即使大的合并会 starve
这k个合并由于在不同的层级,可以并发执行
目的:greedy 策略能够在任意时刻最小化磁盘上的组件数量,组件数量越少,写放大越低
但这种策略在不同的 LSM-Tree 合并模式下性能表现不同
Tiering 显著好于 leveling,在 leveldb 下的性能表现不太行
single:单线程一个接一个层合并,是当前 leveldb 的默认策略;
fair:公平调度策略,当前 Rocksdb 的默认策略;