I/O Passthru (FAST 24) 论文笔记
I/O Passthru: Upstreaming a flexible and efficient I/O Path in Linux (FAST 24)
I/O Passthru: 一种在Linux上灵活高效的 IO 路径
1 Motivation
Problem 1:User Interface Scarcity 用户接口/系统调用的缺乏
Kernel perfers protocol-agnostic abstractions 内核喜欢与协议无关的抽象
- Deal with a variety of devices in a similar fashion. 可扩展性,到多种设备
- Coining a new syscall requires a more generic use case than the NVMe-specific one. 必须具有通用性
- Once added, syscall has to be supported indefinitely. 一旦加入内核,必须长期支持
Problem 2:Poor scalability
various I/O paths in the Linux kernel
路径1:speak file -> FS abstraction 通过文件系统访问存储设备,存取数据
路径2:speak block -> Block abstraction 使用较低级别的接口,与设备文件符交互进行访问
路径3:speak NVMe -> ioctl -> /dev/nvme0n1 NVMe设备专用路径,通过ioctl系统调用,同时附带特定的控制命令直接到 NVMe 驱动
路径1、2性能劣势:多了 FS / Block 抽象层,系统调用开销特别多,频繁上下文切换的开销
路径3性能劣势:ioctl 是同步阻塞式的系统调用,无法利用好 NVMe SSD 高并发吞吐的性能
当前 NVMe passthrough 的限制
通常使用 ioctl 系统调用,包含两种操作码 opcode
1 | |
several limitations:
- 与块设备高度耦合,只兼容部分nvme命令
- ioctl系统调用是阻塞式的,处理大量并发请求时,线程需要等待IO操作的完成,无法充分利用多核和并发能力
- 用户空间和内核空间的复制开销
- 接口仅限有 root 权限用户使用
路径3其他劣势:Poor accessibility 可用性限制,必须要有 root 权限,上云或多租户场景影响很大
Lock to root user
Problem 3:NVMe is not longer tied to block storage
对于 Linux 内核来说,NVMe的新标准、非块语义的新指令功能如何进行适配?
- Multiple command-sets
块语义Block semantics: NVM, ZNS(将存储空间划分为多个区块的存储方式)
非块语义non block semantics: key-value(直接以键值对方式存储和访问数据), computational programs(在存储设备上直接运行计算任务)
- There are newer ways to interact with the storage,NVMe引入了以下几种交互方式
zone append:允许数据顺序写入特定区域,避免传统块存储中的写入冲突,提高写入效率和设备寿命。
FDP write:根据数据的不同特性优化存储位置,减少写入放大
copy command:在存储设备内部进行数据复制
metadata transfer:支持元数据的独立传输和处理

- Many new NVMe commands do not fit into the existing user interface.
Zone-append 和 Copy-offload 等功能虽然在内核层面支持,但如果没有用户空间 API,没有封装好的库函数与系统调用,这些功能对用户程序来说是不可用的。
2 io_uring 特性的介绍
两种模式:SQPoll,IOPoll
- SQPoll 模式(syscall-free submission)
在开启SQPoll模式后,应用程序提交的I/O请求操作将卸载到一个内核线程,从而实现无系统调用的提交
好处:减少了用户空间和内核空间的上下文切换,提高了性能,io每次提交不再需要调用 io_uring_enter
适用于高频率I/O提交场景,相当于有一个专门的工作人员不断检查并处理任务,无需老板亲自下达命令(日志频繁写入)
- IOPoll 模式(Interrupt-free IO)
在未设置IOPoll模式时,对于每个IO完成事件的通知都采用硬件中断,但当 IOPS 较高的场景下,硬件中断会产生较多的延迟和CPU开销
好处:启用IOPoll模式后,应用程序通过轮询完成队列 CQ 来检查IO是否完成,而不是依赖内核中断的通知
适用于高性能场景,相当于各个员工自己检查任务完成情况(数据库处理大量读请求)
另外两个特性:
- batching,一次提交多个IO请求
- chaining,让IO操作自定义有序,比如读后写,可规定依赖顺序
3 设计思想
本文设计目标
- 不依赖与块接口,新接口需兼容所有nvme命令
- 通用用户接口,每次 NVMe 引入新命令时增加一个新的系统调用是不现实的。因此,需要一个能够处理所有现有和未来 NVMe 命令的用户接口,而无需为每个命令单独设计新的系统调用。
- 高效且可扩展,新接口至少与原先的 direct block I/O path 性能相当或更高
- 通用可访问,不仅限于root用户使用
- 最终能合并进linux内核上游仓库
4 IO Passthru 直通技术在内核的架构和实现
三个方面讲述 io passthru 的设计和实现:可用性,效率和可扩展性,可访问性
4.1 可用性
块设备接口的局限性:NVMe 新特性,新命令不支持
解决方案:设计了通用字符设备接口:NVMe generic char interface
为每个 NVMe 命名空间(namespace)创建一个字符设备节点,即使引入了新的命令集,字符接口也会自动支持,无需更改 NVMe 驱动程序代码。
4.2 效率和可扩展性
创建一个异步的 ioctl 替代方案,包括设计 io_uring 命令,big SQE, big CQE
同时引入了两个优化点:fixed-buffer and completion-polling
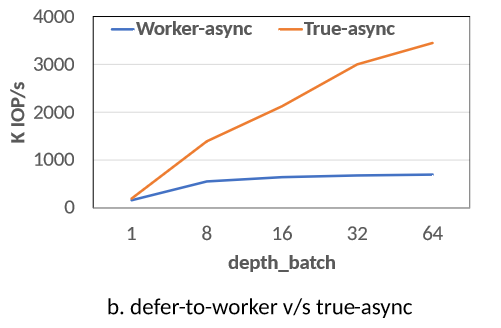
异步 ioctl 实现的两种方式:
- defer-to-worker:传统异步实现,基于工作线程的异步方法,交给专门负责IO的线程,有性能瓶颈
- true-async:完全消除线程阻塞和上下文切换带来的开销,通过 polling 机制实现高效IO
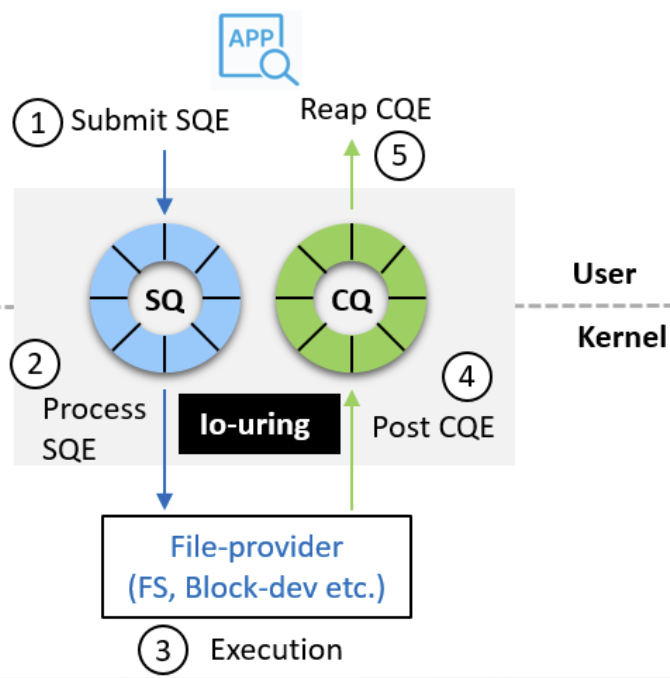
User/Kernel interface
- Communication backbone: shared ring-buffers (SQ and CQ)
- Reduce syscalls & copies
- Programming model
- Prepare IO: Get SQE from SQ ring, and fill it up (fill more to make a batch)
- Submit IO: By calling io_uring_enter
- Complete IO: Reap CQE from CQ ring
- Submission can be offloaded (no syscall)
- Completion can be polled (interrupt-free IO)
1 | |
ioctl
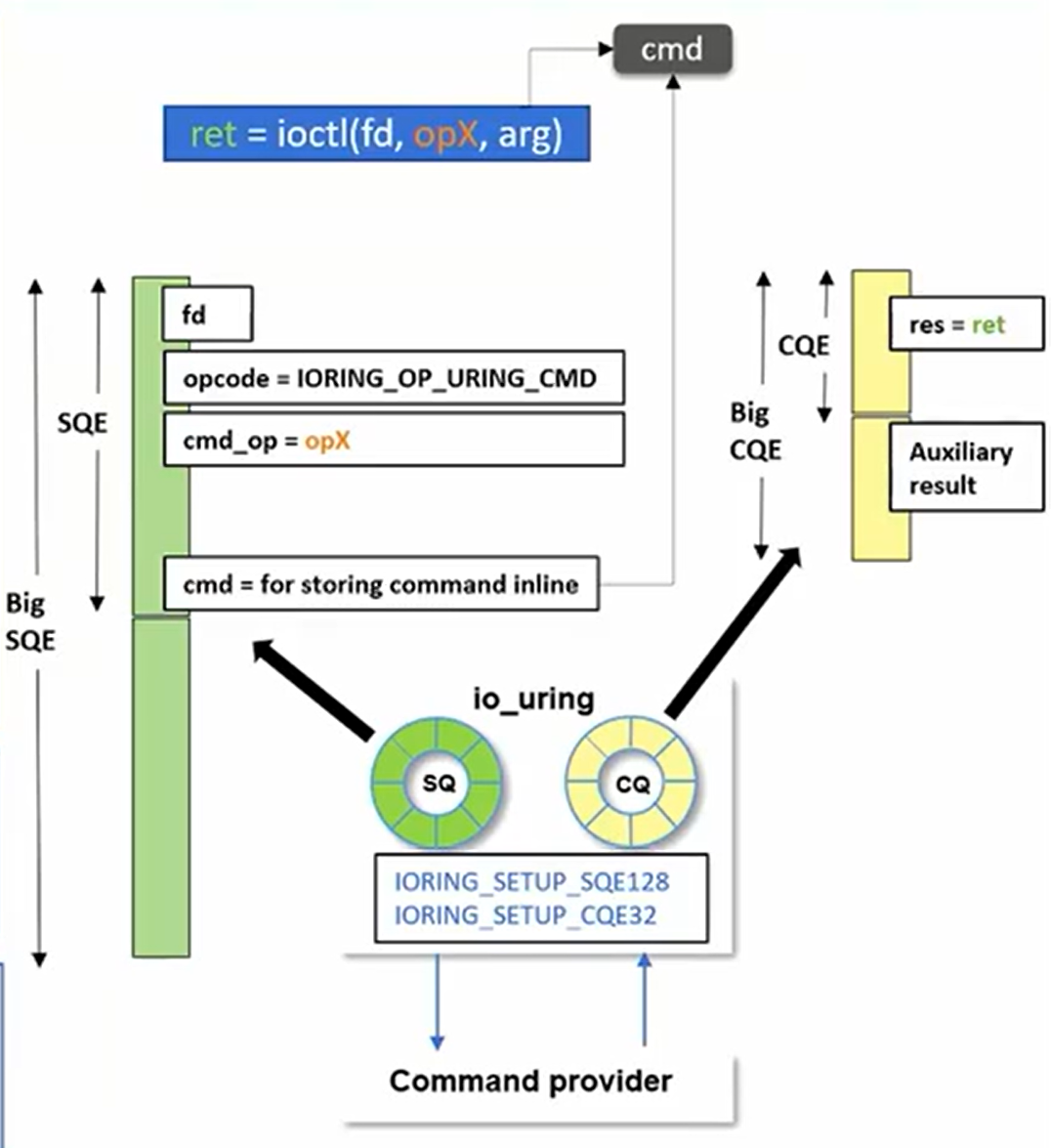
这种设计带来的优点:
- 零拷贝
在用户空间和内核空间同时共享两个队列:提交队列SQE,完成队列CQE
在用户空间中创建 SQE 结构体,无需通过 copy_from_user 进行数据拷贝。结果通过内核创建的 CQE 返回,避免了 put_user 操作。因此,通过在控制路径中实现了零拷贝,减少了数据传输的额外开销。
- 减少线程上下文切换带来的开销
传统的 defer-to-worker 在每次提交IO操作都需要线程之间的切换,有较多开销
true-async I/O 操作的提交和完成都由内核直接处理,用户空间程序无需涉及线程的创建、调度和切换操作,同时也避免了线程的同步开销
两个实现过程中的优化点
- Fixed-buffer
IO操作结束后数据放置在内存缓冲区,原先的设计在分配缓冲区时会先尝试申请内存区域、锁定、释放,而 io_uring 通过复用先前已锁定的缓冲区减少了申请、锁定、释放的开销
- Completion Polling 完成队列轮询
应用程序通过轮询完成队列 CQ 来检查IO是否完成,而不是依赖IO完成后硬件中断的通知
4.3 可访问性(访问控制)
文件模式表示指定了文件的访问权限,当用户程序想直接与硬件设备进行交互时,NVMe驱动程序会进行二级检查,然而,NVMe 驱动程序通过一个粗粒度的 CAP_SYS_ADMIN 检查来保护所有的直通操作,完全忽略文件模式,导致直通接口受限于 root 用户。
解决方案:修改 NVMe 驱动程序,实现了一个细粒度的访问控制策略
根据命令类型,管理命令/ io命令进行了权限划分,让一般用户也能直接操作硬件;
同时,作者也引入了强制访问控制(MAC)的机制,进一步加强了对这些操作的管控。
6 IO passthru 可扩展性和灵活性:NVMe 新接口、新特性的适配
6.1 FDP命令
NVMe FDP tackles this problem of high WAF by segregating I/Os of different longevity types in the physical NAND media.
FDP:Flexible data placement 灵活数据放置指令,最新的一种引导数据放置的标准
Linux内核先前开发了基于写提示的基础设施允许应用端在写操作时同时发送放置提示,但现在这个基础设施已经被 Linux 主线移除;
IO passthru 作用:在应用端利用异步IO时可以同时发送放置提示,而不必担心FDP垂直集成到内核存储堆栈的各个部分。
FDP的优势:通过在物理 NAND 介质中分离不同寿命类型的 IO 来解决写放大的问题;
SSD写放大问题出现的根源:在 SSD 上,数据的写入并不是简单的覆盖旧数据,而是需要将旧数据和新数据混合在一起管理。混合不同寿命(写入频率和保留时间)类型的数据会导致更多的内部数据迁移和垃圾回收,从而增加 WAF。
FDP的实际效果:
- 降低 WAF:由于减少了不同寿命数据的混合,内部数据迁移和垃圾回收的效率提高,写入放大系数显著降低。
- 提高 SSD 性能和寿命:较低的 WAF 意味着 NAND 媒体的磨损减少,SSD 的寿命延长,性能也更稳定。
6.2 计算存储架构
将计算能力直接集成到存储设备中,减少数据传输,提升性能。
NVMe标准新提出的两个命名空间,通过这两种命名空间管理内存资源和计算资源:
- Memory Namespace
- Compute Namespace
所有新的NVMe命令都可以通过I / O Passthru接口高效地下发,这使得用户空间能够在不改变内核的情况下利用计算存储。
7 实验
实验配置:

实验1:对比 passthrough IO path 和 block IO path 的效率,确定两者的峰值性能
图a:general kernel config 默认配置
图b:optimized kernel config:禁用CONFIG_RETPOLINE 和 CONFIG_PAGE_TABLE_ISOLATION 选项,内核之所以默认开启这两个选项的原因:缓解 spectre 和 meltdown 硬件缺陷
SSD 硬件规格:最大读性能:5M IOPS,只有 BASE + FB + POll + optimized kernel config 做到了
FB:fixed-buffer 优化 (申请、锁定、释放缓冲区的开销减少)
Poll:降低了中断和上下文切换的开销
原因:io passthru 比 block io_uring 涉及的处理更少,其跳过了 split,merge,io scheduling
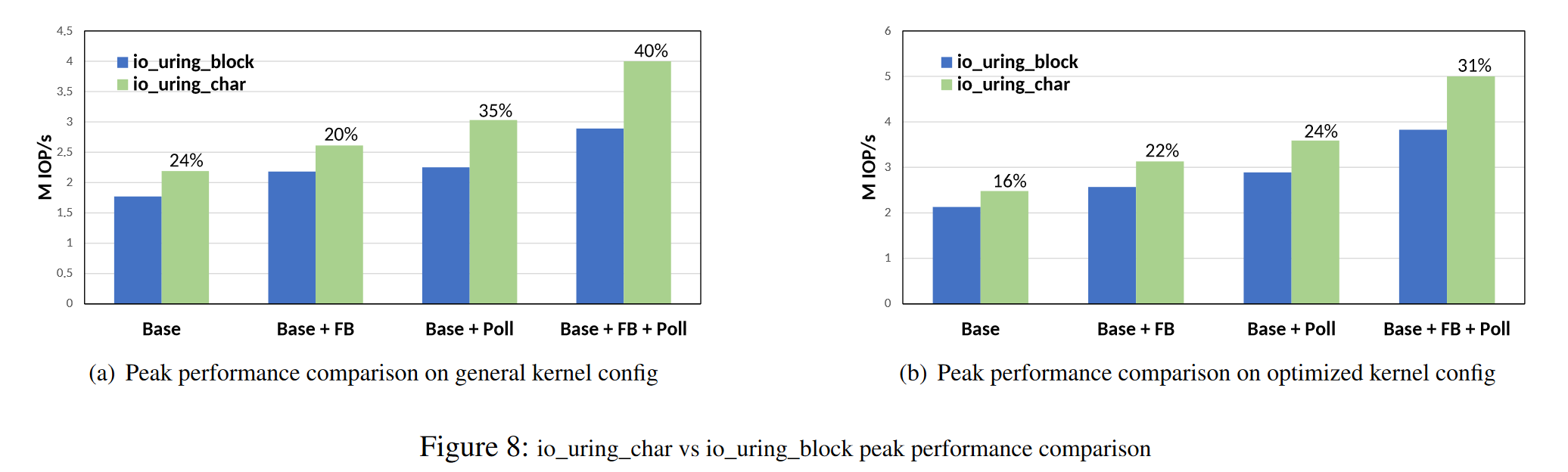
图9:
a图:CPU利用率、提交延迟和页面大小的关系图
- 对比了不同页面大小 4KB, 16KB, 64KB 的提交延迟,4KB 利用率最高
- fixed-buffer 减少了 IO 的提交延迟和 CPU 利用率
b图:对比队列深度与可扩展性
- 随着队列深度的增加,可接受的请求数量增加,IOPS持续增加
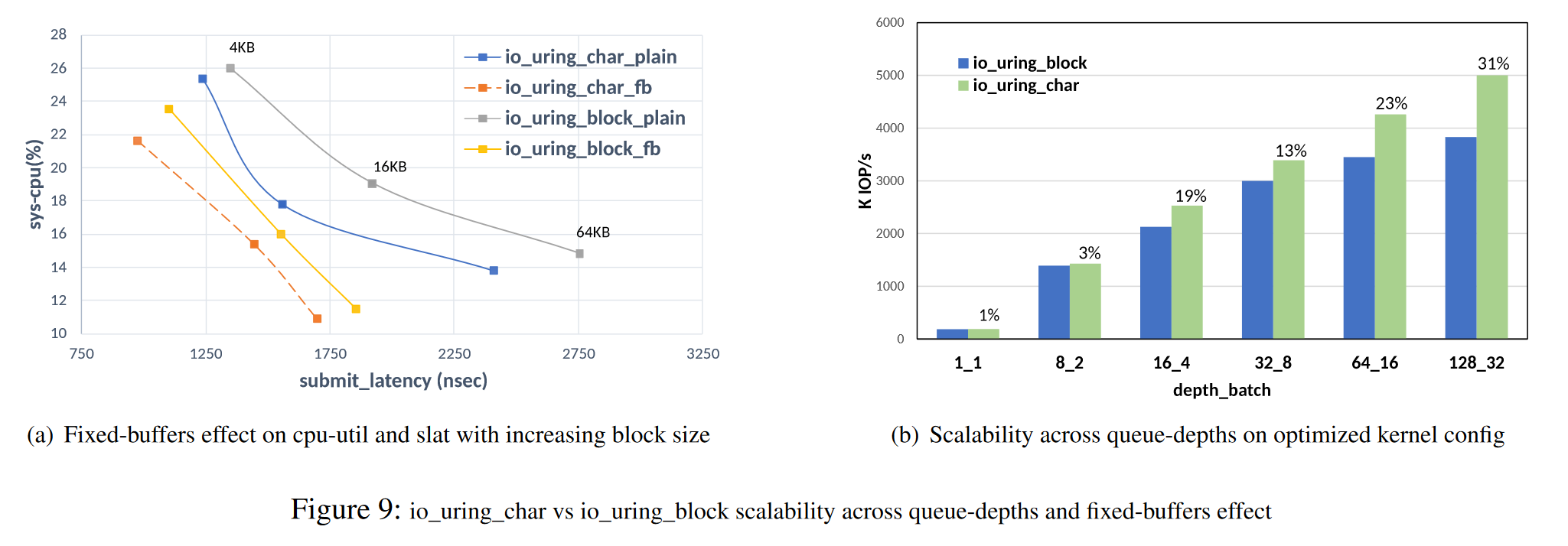
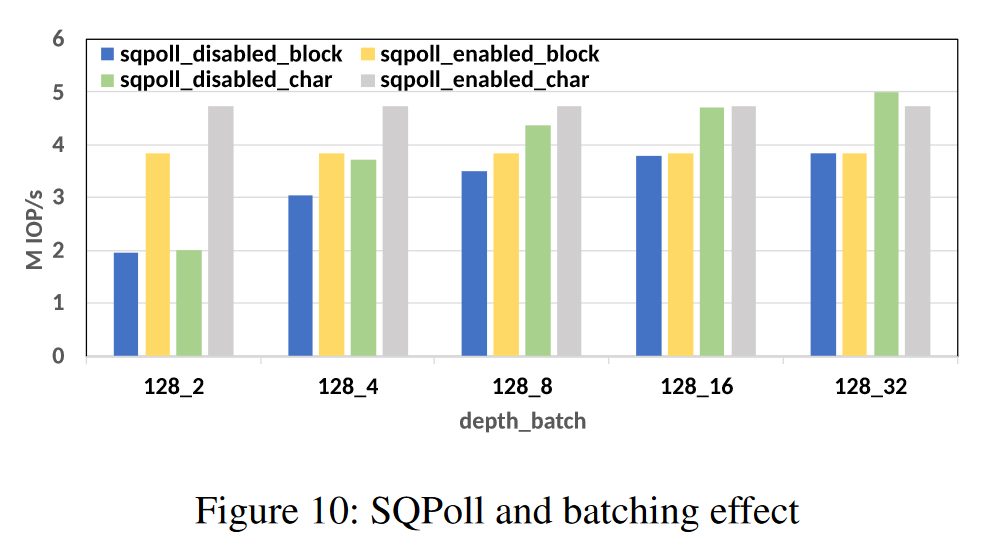
图10:对比 SQPoll 和 批处理 对吞吐量的影响
SQPoll 减少了系统调用的开销,对 block 和 passthrough path 都能提升吞吐量
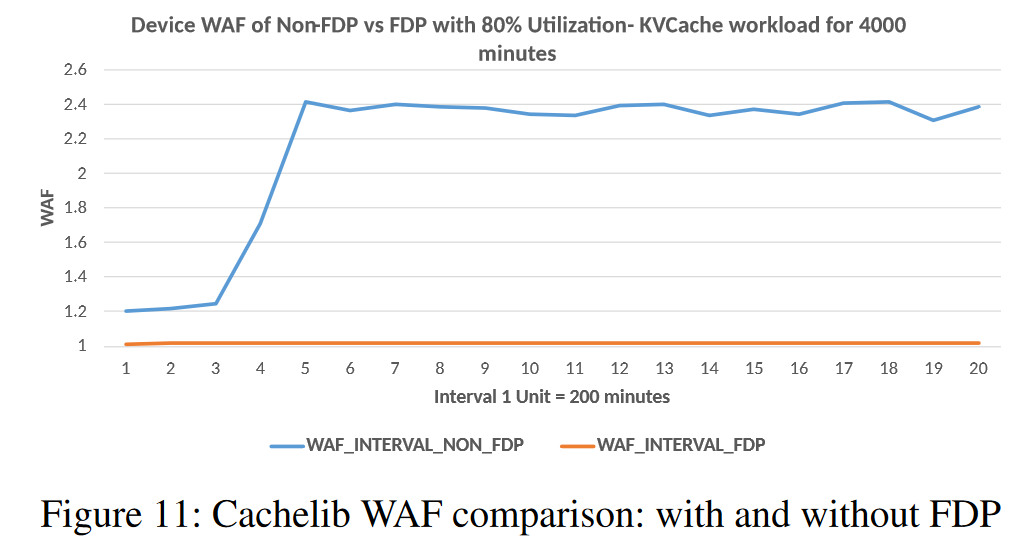
实验2:
将 IO passthru 接口与上层应用 Cachelib 相结合,并对比是否启用 FDP 对写放大的影响
使用 write-only KVcache 工作负载进行了实验,在没有放置提示的情况下,SSD的写放大上升到2.4倍之多,而在使用 io passthru 接口并启用 FDP 后,写放大趋近于1
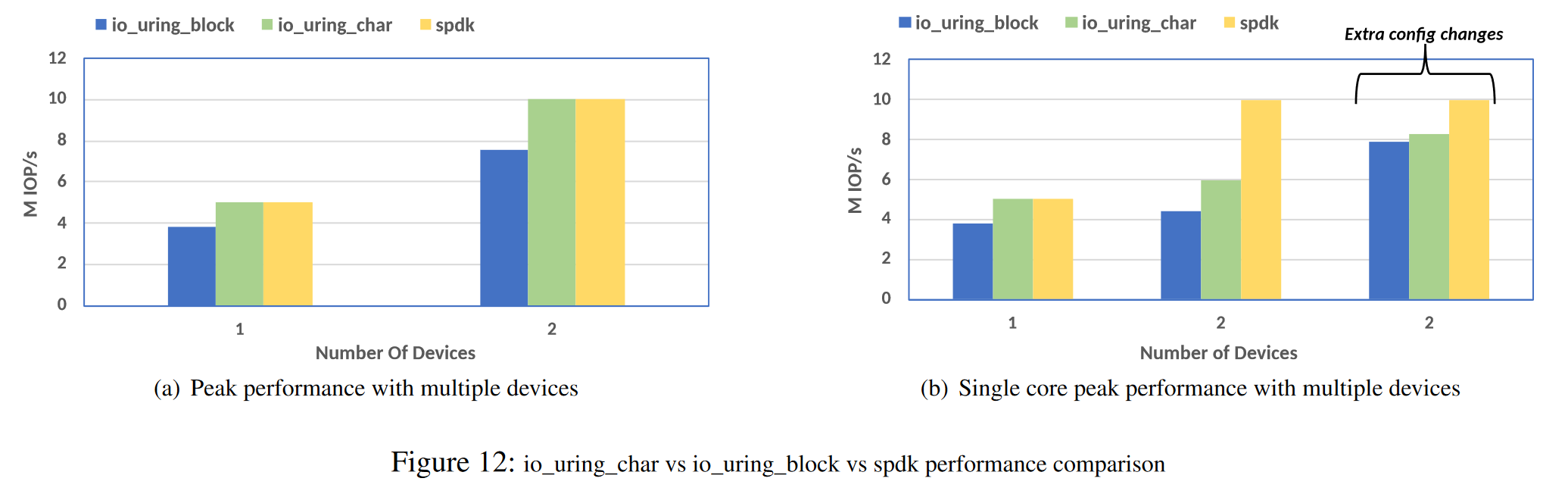
实验3:IO passthru 与 用户态的 SPDK 做对比
a图:两个CPU核连接两个 SSD设备,IO passthru 减少了与 SPDK 的性能差距
b图:单个CPU核连接多个 SSD设备,性能上仍落后于 SPDK,原因如下:
- SPDK在用户态,对 NVMe 设备独占拥有权
- I/O Passthru 需要使用块层的特性,例如硬件队列抽象、标签管理、超时/中止支持等。这些特性增加了 I/O 路径中的额外处理负担
- IO passthru 经过内核,还是免不了系统调用的开销
8 总结
随着新的存储特性、存储规范的增加,Linux 内核缺乏充足的系统调用与接口,面临适应性的挑战;
作者提出了一个新的选择,通过在内核中添加新的 IO Passthru 来解决这个问题。
这个路径通过使用新的 NVMe 字符接口并与 io_uring 相结合,扩展 io_uring 并提出同步阻塞式系统调用 ioctl 的替代方案,为当前/未来的 NVMe 新特性提供了支持。