充分利用NVMe SSD特性提升OLTP存储引擎的性能 (VLDB23)
What Modern NVMe Storage Can Do, And How To Exploit It: High-Performance I/O for High-Performance Storage Engines (VLDB 23)
现代NVMe存储可以做些什么,我们在存储引擎上如何更好利用高性能的 IO
摘要
基于闪存的 NVMe SSD 不仅便宜还具有高额的吞吐量,在将多个SSD集成到一个服务器上后,可以实现每秒千万级别的IO操作。
我们的实验表明,现存的 out-of-memory 数据库 和 存储系统并没有充分利用这种高性能的优势,在本篇工作中,我们通过优化IO存储引擎缩小了软硬件之间性能上的差距,在大于内存容量10倍的数据集中,我们系统达到了每秒百万的 TPC-C 事务。
1 介绍
关于闪存,近年来闪存SSD替代传统磁盘成为默认的存储介质
传输协议方面,传统的SATA接口逐渐被 PCIe/NVMe 接口所取代;
存储吞吐量方面,单个SSD可以实现百万级的随机IO操作;
现代服务器逐渐支持每个插槽128个PCIe通道,可以轻松在全带宽下承载8个SSD;
鉴于傲腾NVM商业上的停产,作者认为闪存是支持大型数据集经济且高效的方式;
现有数据库系统的存储性能差距
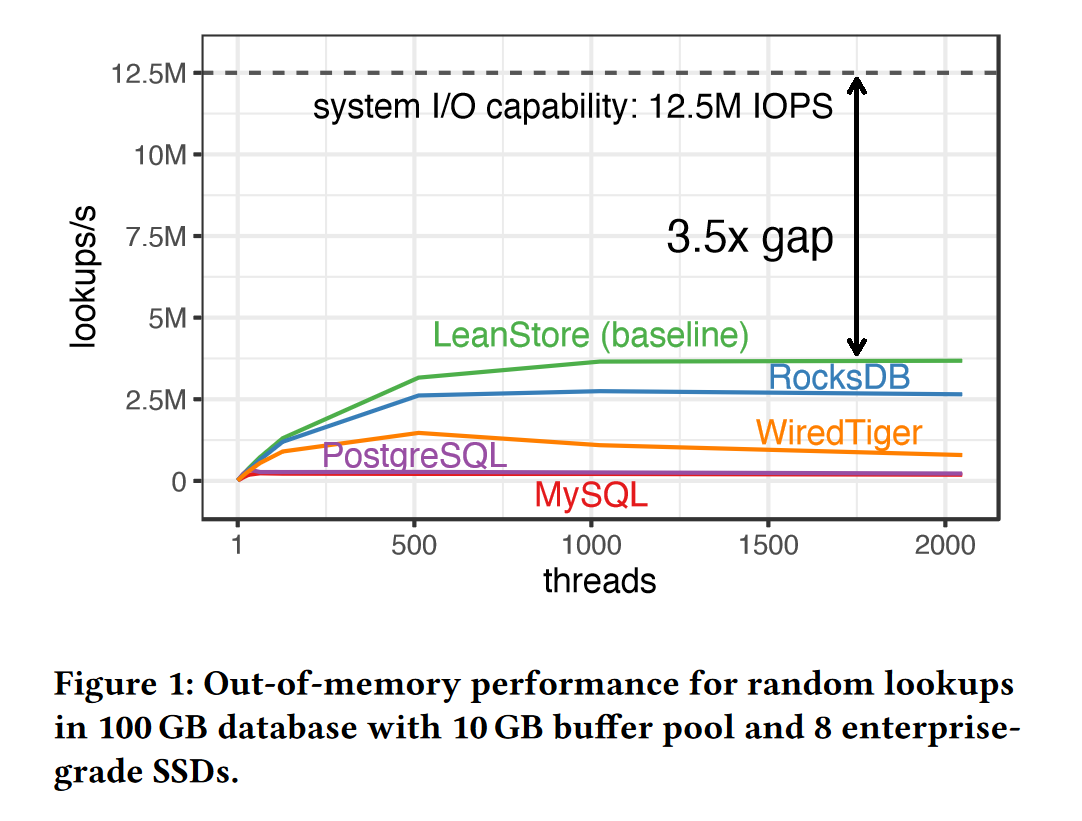
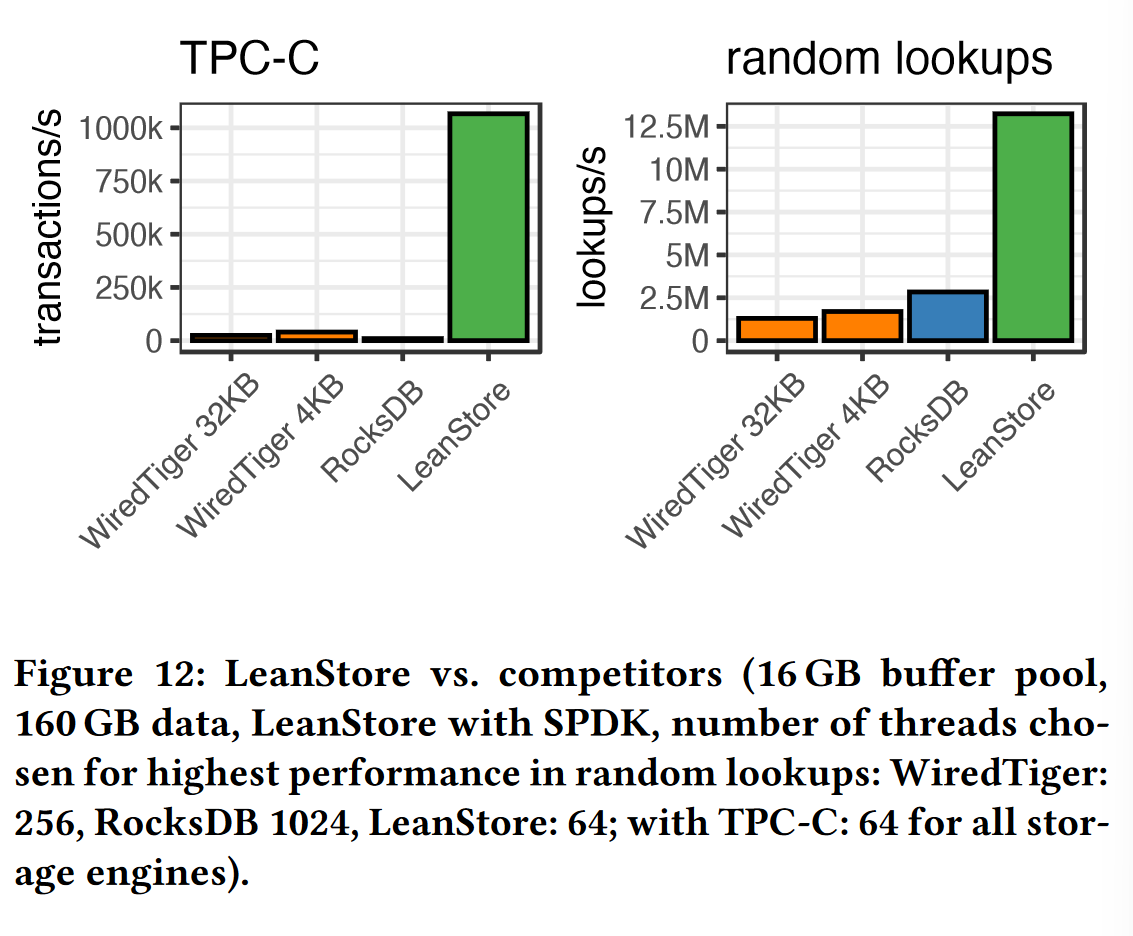
图1是对几个 out-of-memory 数据库系统查找性能进行的实验,这些数据库分别通过内存缓冲池cache,LSM-Tree,B+树等数据结构进行索引查找,实验中采用了8块闪存SSD,每块支持每秒1.5M随机4KB读,因此服务器最高支持 12.5M IOPS。
但从实验结果来看,对闪存专门做了优化的 Leanstore 数据库也仅有每秒3.6M随机读,与系统最大支持的 IOPS 相去甚远。
本篇文章研究目标是如何缩短这一存储的性能差距,可以分解为以下几个研究问题:
1、NVMe SSD 阵列能否在实际工作中达到硬件规格中承诺的性能?
2、哪一种 IO API 在存储系统中最应该被使用:POSIX API,libaio,io_uring?
是否有必要上 SPDK,基于内核旁路的 IO?
3、为了降低IO放大,存储引擎维护的页面大小选多少合适?
4、如何确保SSD吞吐量所需的并行性,同时多少IO并发请求能使系统性能最大化?
5、如何设计存储引擎,使得它支持千万级别的 IOPS?
6、IO操作应该交给专门的IO线程处理,还是每个工作线程自己处理性能更好?
2 What Modern NVMe Storage Can Do
2.1 SSD的可扩展性,根据第一个问题进行实验
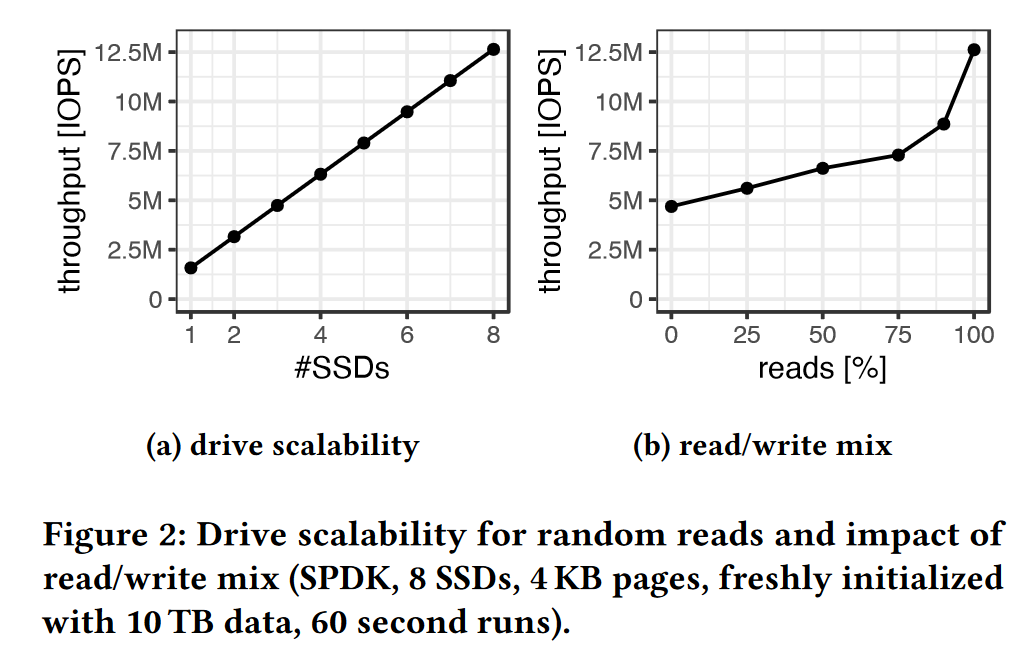
从图2可以看出,在接了8块SSD的服务器上测试后,总吞吐量能够达到预期的12.5M IOPS;
事务型工作负载通常是写密集型的,右图通过改变读数据的占比,得到服务器最佳的硬件性能。
2.2 页面大小的权衡
大多数数据库尽可能选择大的页面,比如:8 KB (PostgreSQL, SQL Server), 16 KB (MySQL, LeanStore), 32 KB (WiredTiger-MongoDB)
大页面带来的好处:
- 性能提升,更多的数据可以在一次访存中被读写,减少了访存的次数
- 减少了缓冲池需要管理的页面数量,减少了缓冲池管理的开销(元数据,索引)
- 充分利用带宽
大页面带来的坏处:
- 过大的page size可能会导致IO写放大:
1、对于16KB页面,写入100B数据需要磁盘向内存完整传入整个页面,造成多余的160倍的额外IO读写
2、对于4KB页面,写入100B数据需要磁盘向内存完整传入整个页面,造成多余的40倍的额外IO读写
因此,用4KB页面比16KB页面要减少4倍的写放大。
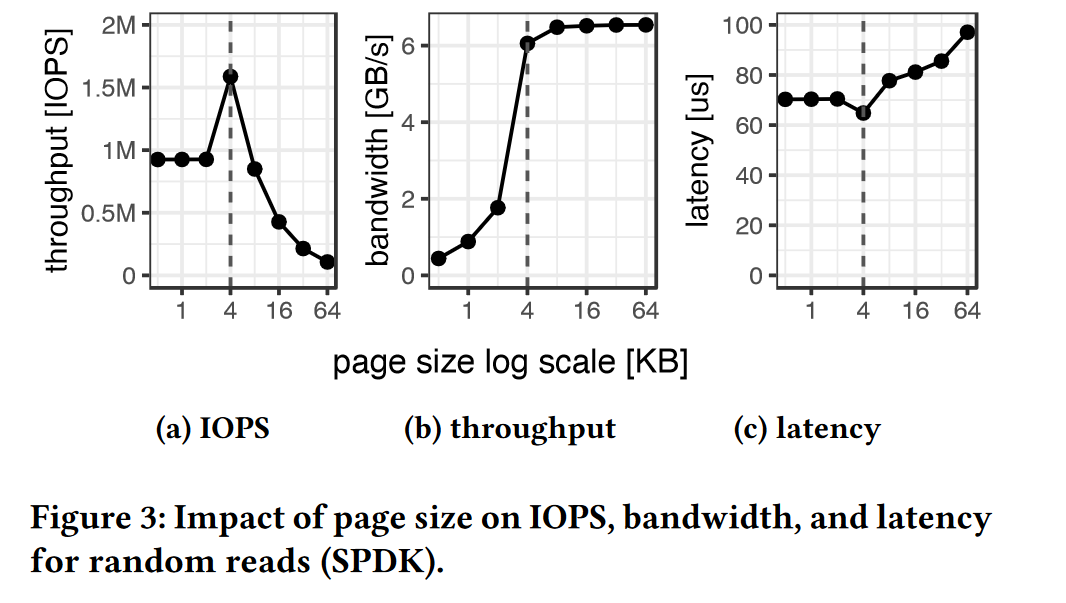
图3做了对比工作,当页面大小为4KB时,吞吐量最高,带宽充分利用,延迟最低。
另外,对于更小的页面,IOPS和延迟都差的原因在于,闪存翻译层的开销较高。
2.3 SSD的并行
SSD是可高度并行的设备,闪存的随机读延迟约为100us,比磁盘快100倍,比内存慢1000倍;
如果使用同步访问请求,将只有 10K IOPS,或 40MB/s
根据IO并发量的不同,做了图4的实验:
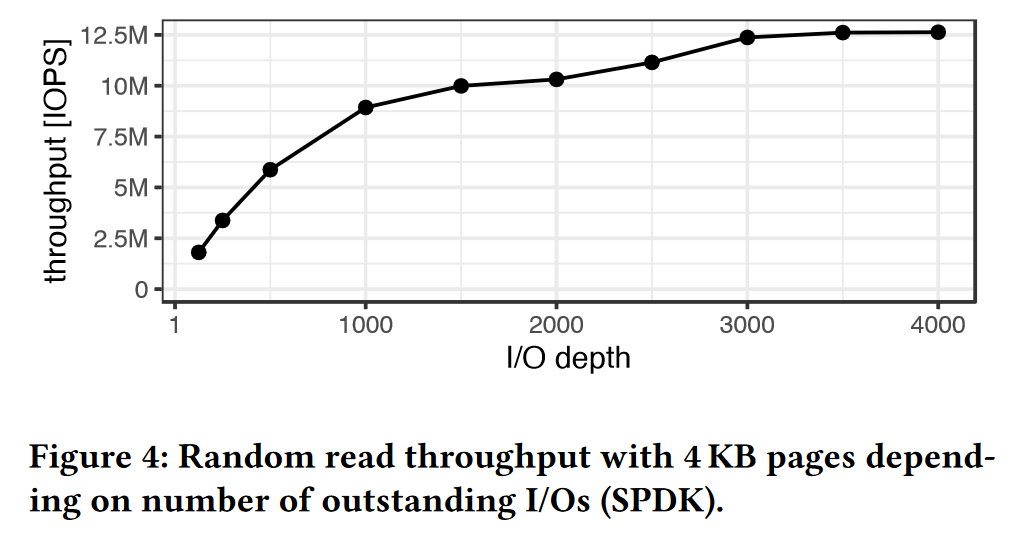
想要获得良好的性能,至少同时1000个IO并发请求,每个SSD125个左右;
想要系统IO达到吞吐量的饱和,至少同时3000个IO并发请求。
2.4 IO接口
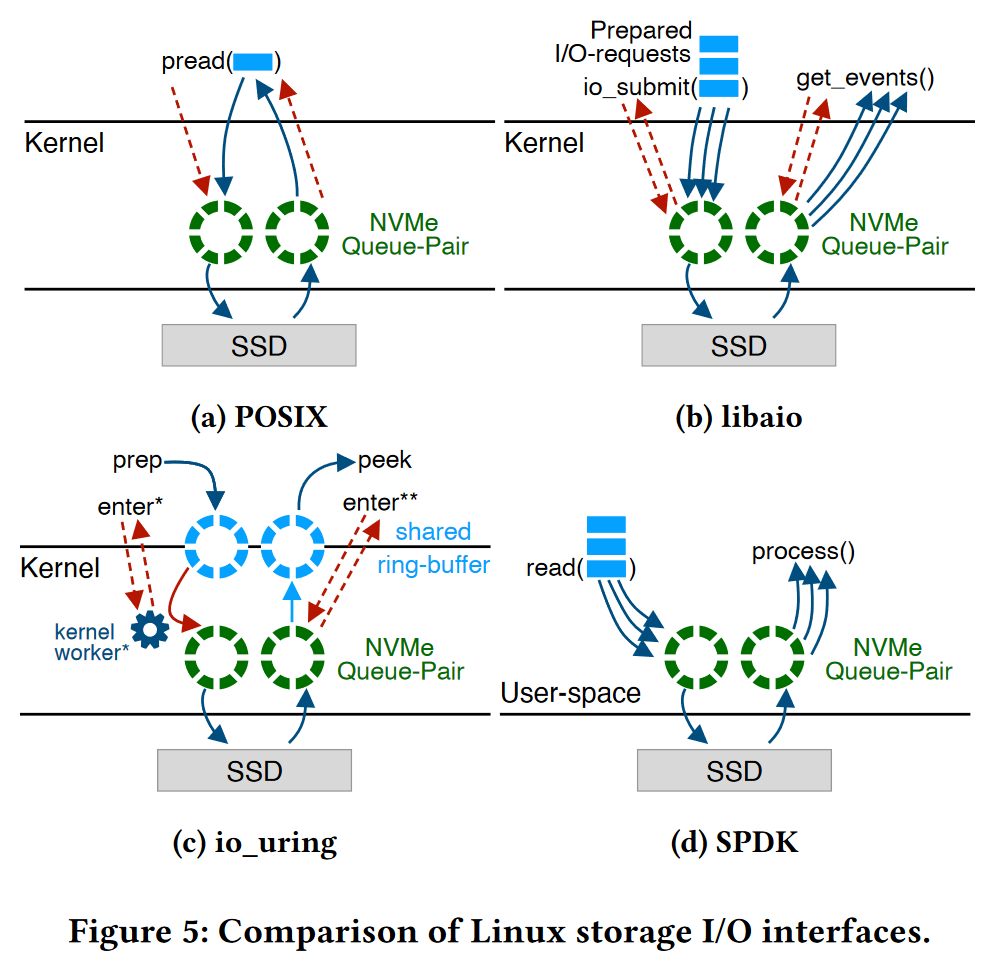
- POSIX API 阻塞式同步IO
pread,pwrite,用户线程发出IO请求,将请求交给内核,此时用户线程进入阻塞状态,被CPU移入阻塞队列,内核线程将判断数据是否从磁盘传输到内存,直到数据完成传输后,将数据传入用户空间,此时拷贝完成,唤醒用户线程。
- libaio
允许一个系统调用提交多个 IO请求,允许应用程序发起异步I/O请求,然后继续执行其他任务,而不必等待I/O操作完成。异步I/O操作通过io_submit()函数提交I/O请求,然后通过io_getevents()函数获取完成的I/O事件。
- io_uring
在用户空间和内核空间分别设置了两个队列:提交队列SQE,完成队列CQE。
SQE用于用户线程向内核提交异步IO请求,CQE用于用户线程从内核接收完成的异步IO操作
io_uring与aio的区别在于:
1、libaio 仅支持 O_DIRECT 模式下的访存,io_uring 支持所有模式,同时也支持网络通信;
2、libaio一些内部实现仍采用阻塞式进行,比如元数据访存,设备不足时阻塞式等待;
3、libaio开销较高,需要一些额外的拷贝;
4、io_uring能够解决上面所有问题的同时,具有更强的性能和可扩展性。
- SPDK 绕过内核的存取方式
SPDK库可以让用户空间线程直接将IO请求写入 NVMe请求队列,完全绕过系统内核
2.6 确定 leanstore IO性能下降的来源
1、并行度不够
leanstore使用的是传统的 POSIX API (O_DIRECT),工作线程使用同步IO操作处理缓冲区出现的页错误,每个请求都需要进行至少一次与内核的上下文切换,并在IO完成之前有阻塞。
2、过度订阅问题
当有大量的工作线程争夺剩余的CPU核心时,会导致非常高的上下文切换开销;
工作线程数量 > 系统最大支持的线程数时,调度延迟、资源竞争、上下文切换都会导致性能下降
3 如何设计 IO 优化的存储引擎
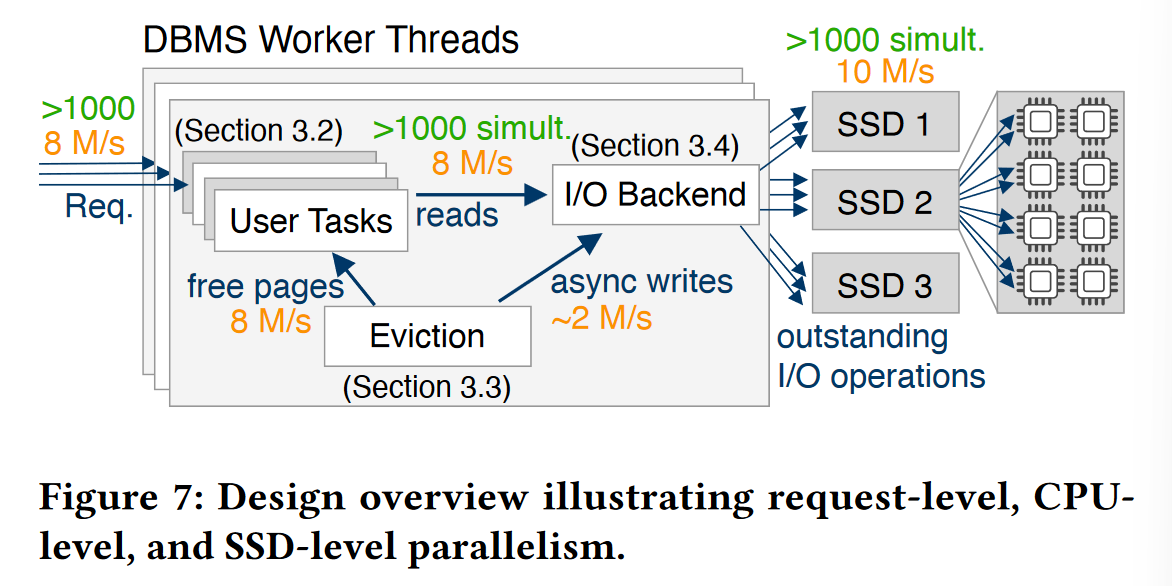
1、让系统每个模块充分利用并行性
总览
- 每个工作线程可以同时接收数千级的并发请求,每个请求由工作线程内部的轻量级用户协程处理
- 当请求涉及到I/O存取时,User Task 将换页请求发往I/O后端,当前协程被挂起 (await)
3.2 如何在不引起线程超额订阅情况下,合理管理大量并发请求
- 引入协程:如何在不引起线程超额订阅情况下,合理管理大量并发请求
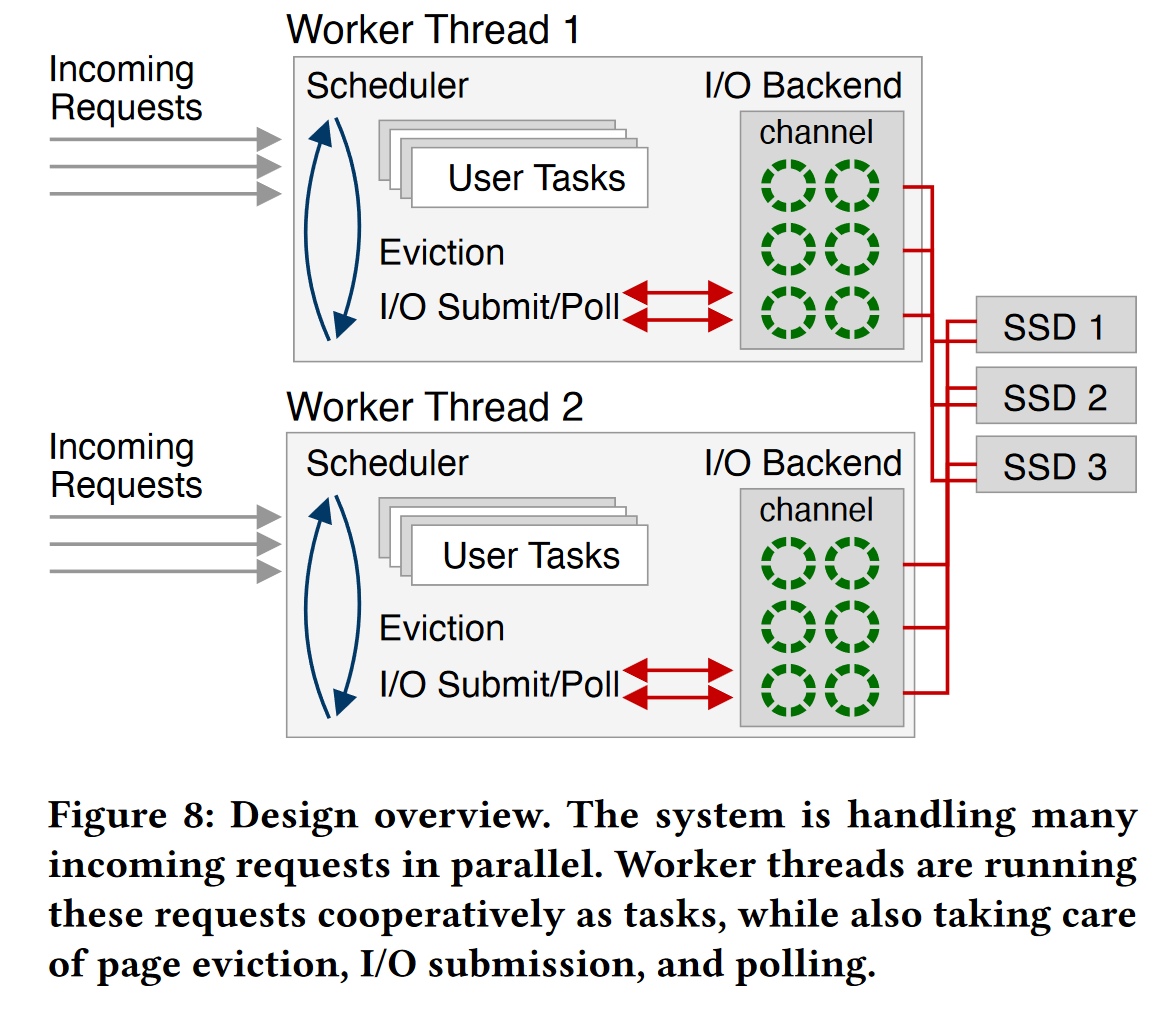
1、为避免超额订阅,工作线程的最大数量 = CPU物理核心数
但由于并发请求的数量是数以千计的,这里用到了新的思想,每个工作线程调度多个协程。
2、每个工作线程内部维护一个调度器,用于调度轻量级协程 User Task 的进行;
这里用的轻量级协程来自 Boost.Context 库,通过作者的测试,一个协程任务的切换,只需要20个CPU周期,而一个内核上下文切换需要几千个CPU周期。
3、这种非抢占式的协程调度意味着不能再使用同步阻塞式IO,因为它会阻塞整个工作线程。
因此,工作线程将使用非阻塞式异步IO接口,比如:libaio,io_uring,SPDK
当发生缺页时,IO请求将被提交到IO后端,并将当前协程的控制权交还给调度器,调度器会轮询并执行就绪的协程。
3.3 具体的执行流程例子
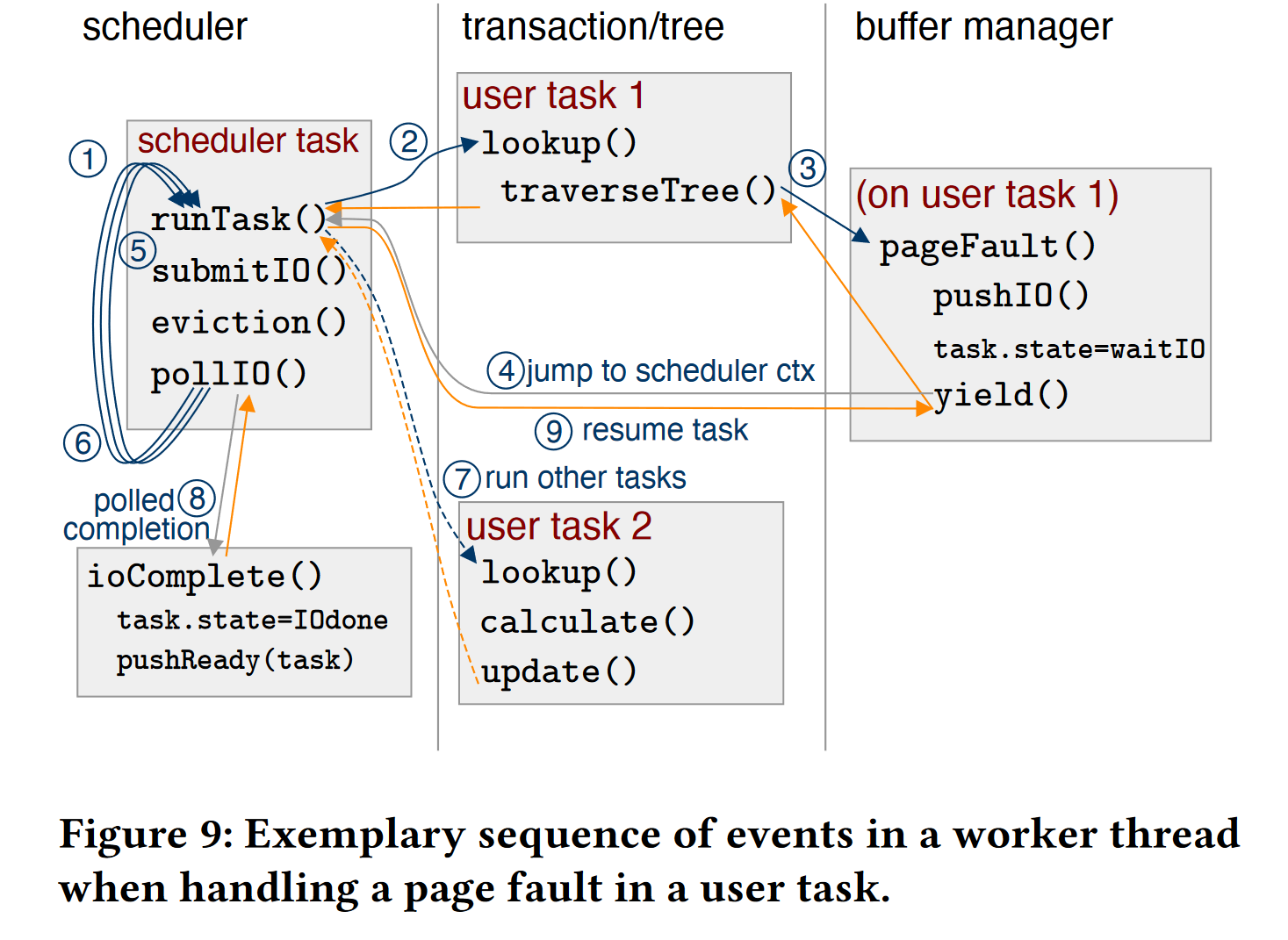
在原先设计的 Leanstore 存储引擎中,缺页时的页面替换,异步IO任务都交由后台线程完成,但缺点在于当工作负载发生变化的时候,我们很难知道后台线程的数量,难免会发生过度订阅,花更多的时间在切换上下文。
作者这里提出的观点是,由于协程和异步IO的加入,我们可以将这类后台线程放到前台,作为协程交给调度器调度,整个执行过程以图9为例:
- 工作线程收到一个查询请求,需要通过遍历索引查找某项数据,于是创建协程的上下文,运行 user task1
- 但在 task1 运行的过程中发现,这个页面不在内存中,这触发了缺页,这将生成一个IO请求,并将提交这个IO请求到IO后端,yield关键字会将当前协程挂起,并将控制权返还给调度器。
- 调度器会轮询自己的任务队列,触发向SSD提交IO请求,页面替换任务,并交由IO控制器
- 当有新的请求 user task2 到来时,若数据都已存在内存中,task2 将继续执行直到完成
- 当 task1 的IO页面调度完成后,IO后端将调用 callback 函数通知调度器可以继续执行 task1
3.4 I/O模型的对比与选择
- Dedicated I/O Threads Model
实现简单,在这种模型中,工作线程无法直接访问 SSD,而必须与处理 I/O 的专用 I/O 线程进行通信,这种专用I/O线程作为内核工作线程,处理大量I/O请求时需频繁切换上下文。
- SSD Assignment Model
每个SSD分配给对应的工作线程,目的是改进缓存的局部性和减少轮询;
但系统在实际的运行过程中,每个工作线程需要与其他工作线程进行通信,以访问其所分配的 SSD,带来同步的开销。
- All-to-All Model
每个工作线程都可以访问所有的SSD,线程之间不再需要传递I/O消息。
Leanstore 存储引擎原本的实现基于 Dedicated I/O Threads 模型,用的是传统的同步阻塞I/O
但为了更好的利用SSD并行性和异步I/O带来的优势,本文选择了 All-to-All 模型;
为了能更好反映 tradeoff,作者基于后两种I/O模型在两个异步I/O库上分别做了以下实验:
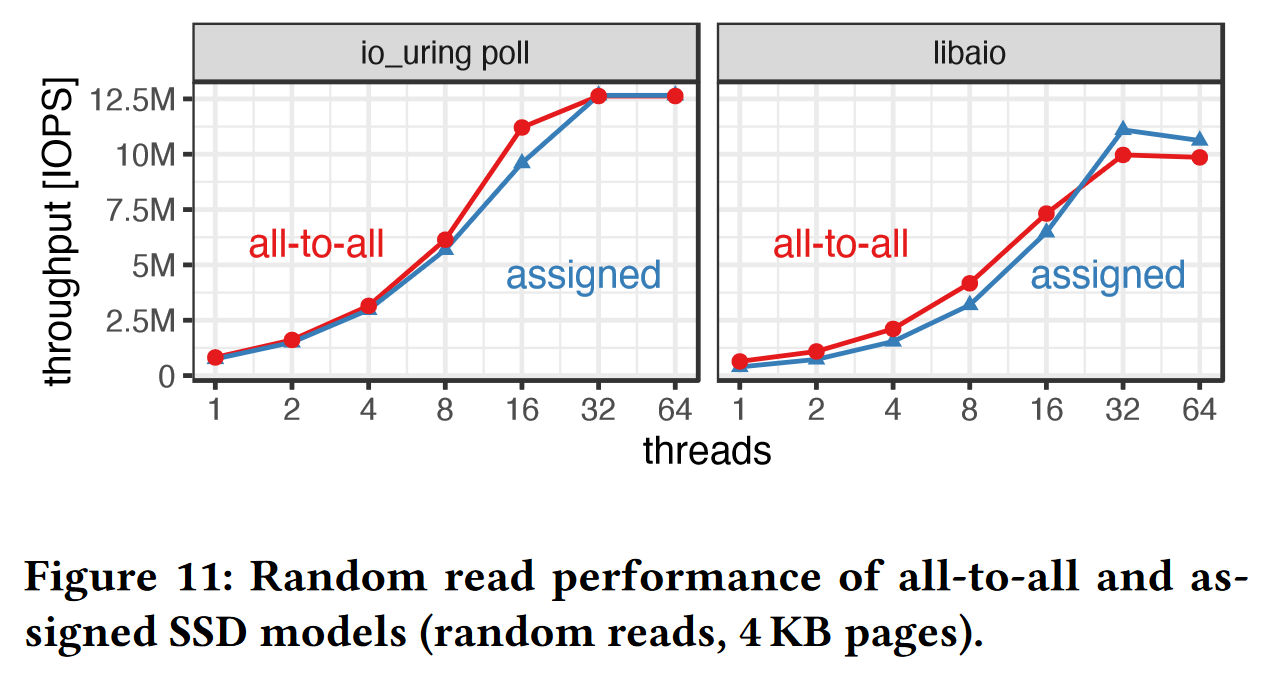
由于本文基于多个SSD设备,需要一个RAID的软件解决方案
Linux md raid(Multiple Device RAID)是 Linux 内核提供的软件 RAID 解决方案,但它存在一个硬限制:the Linux md raid seems to have a hard limit at around 15 GB/s.
因此,本文实现了一个 RAID0 级别的数据条带化抽象:
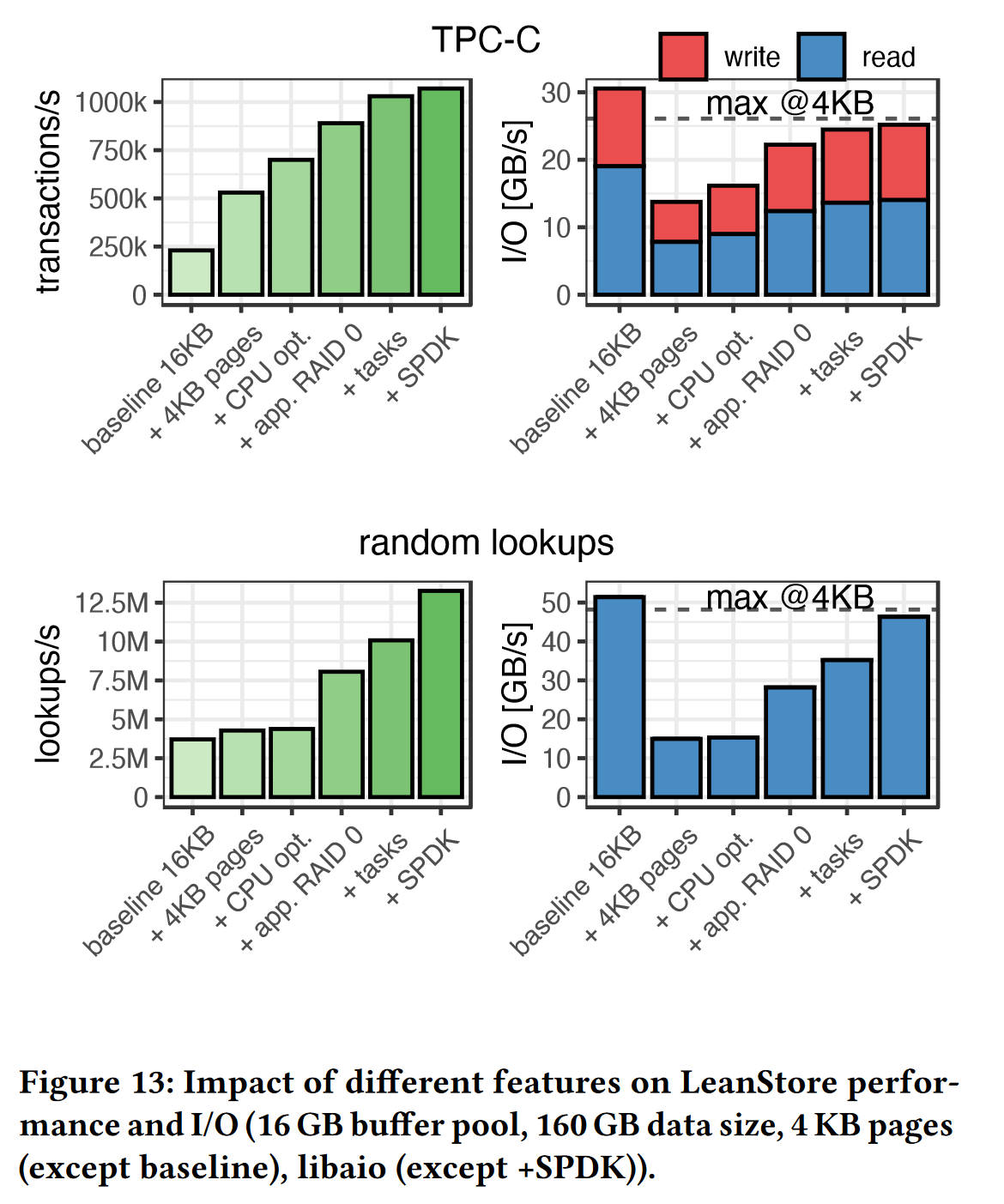
在图13的消融实验中,可以看到一个较高的吞吐量的提升。
RAID0:无容错设计的条带硬盘阵列,以条带形式将RAID组的数据均匀分布在各个SSD中
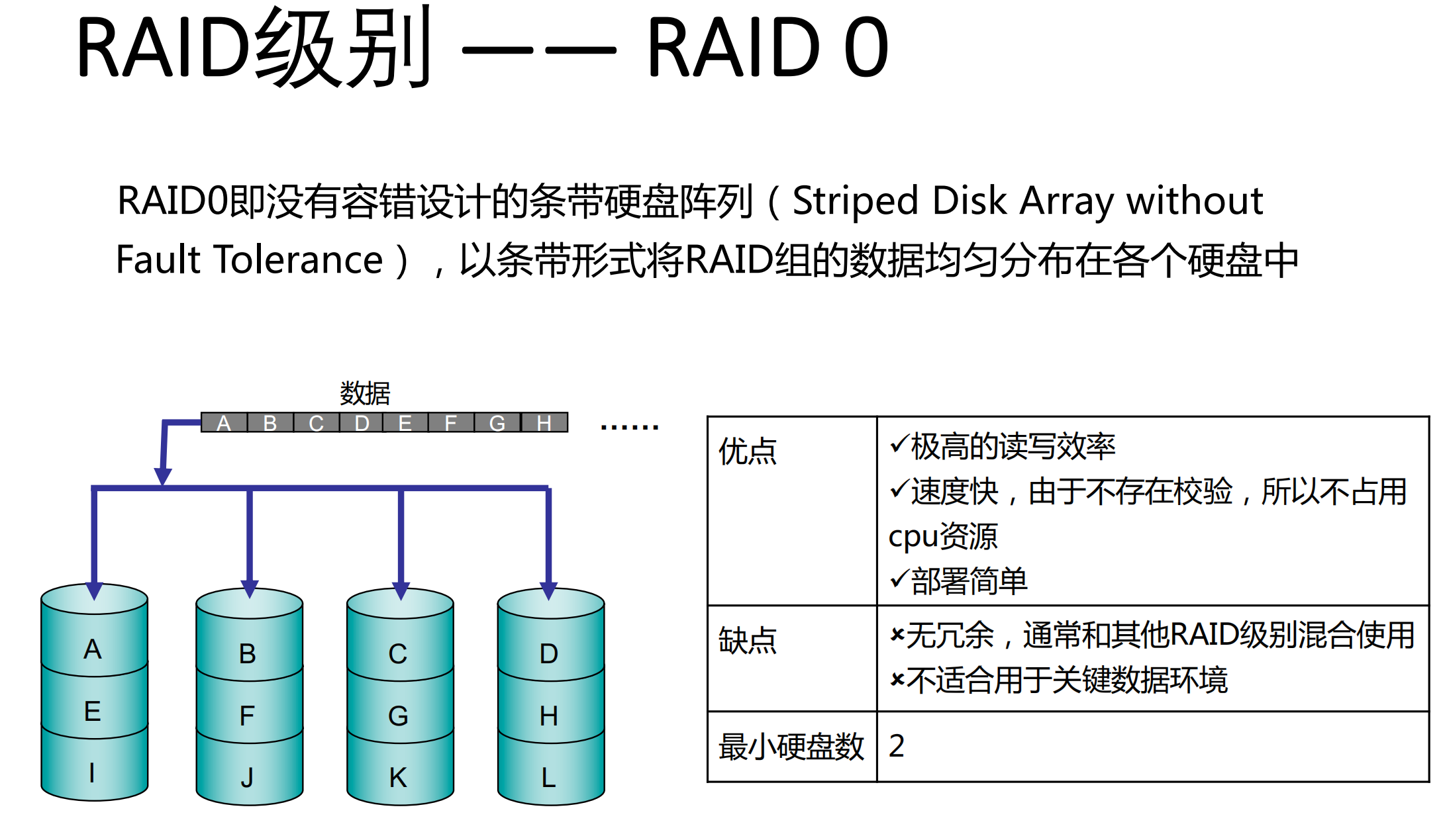
3.5 CPU部分的小优化
主要是页面替换方面,通过引入乐观父节点指针减少树的遍历次数节约CPU时间
leanstore 管理页面的方式:用B+树同时管理内存和磁盘中的页面,将页面分为 hot, cooling, cold 三类
在原本的leanstore baseline中,页面驱逐分为两个阶段:
- 第一阶段,随机页面被选取,并放入 cooling 队列
- 第二阶段,从 cooling 队列取出页面进行替换,替换后的页面标记为 cold
本文的优化在于,当某个内部节点的所有叶节点被 unswizzled 后,它应立即被放入 cooling 队列,但由于原先的实现B+树没有从叶节点指向父节点的指针,只能从根节点遍历,浪费大量的CPU周期(测出大约占10%CPU时间),而如果盲目对每个节点加入指向其父节点指针,会带来一笔空间上的开销。作者用了乐观父节点指针方法减少了树的遍历,但这里我个人认为算是小优化。
对于内部节点,只有它所有的叶节点都被 unswizzled 后,它才允许被替换
4 实验部分
- 实验1:比较系统之间的性能,其中 leanstore 的存储引擎采取了本文提到的若干 I/O 优化
- Ablation Study. 对比各项优化对系统整体性能提升的影响
- baseline 在相同负载情况下,事务吞吐量和随机查找性能较低,但带宽很高,这是由于 baseline 默认页面大小为 16KB
实验2,消融实验,对比各个优化对系统整体性能提升的影响
baseline在相同负载情况下,事务吞吐量和随机查找性能较低,但带宽很高,这是由于baseline默认页面大小为 16KB
(可以理解为在相同并发请求下,带宽是有限制的)
- 4KB在TPCC负载下有比较大的TPS提升,是由于减少了写放大
- CPU的小优化,提升不算大,页面替换时占用的CPU周期缩短约5%~10%
- 作者自己设计的RAID0解决方案,没有了linux md raid的硬限制,有一定的提升
- 协程级别的task,避免了过度订阅,减少了内核上下文切换所需的CPU周期
- SPDK,异步IO,绕过内核直接在用户空间与SSD进行读写
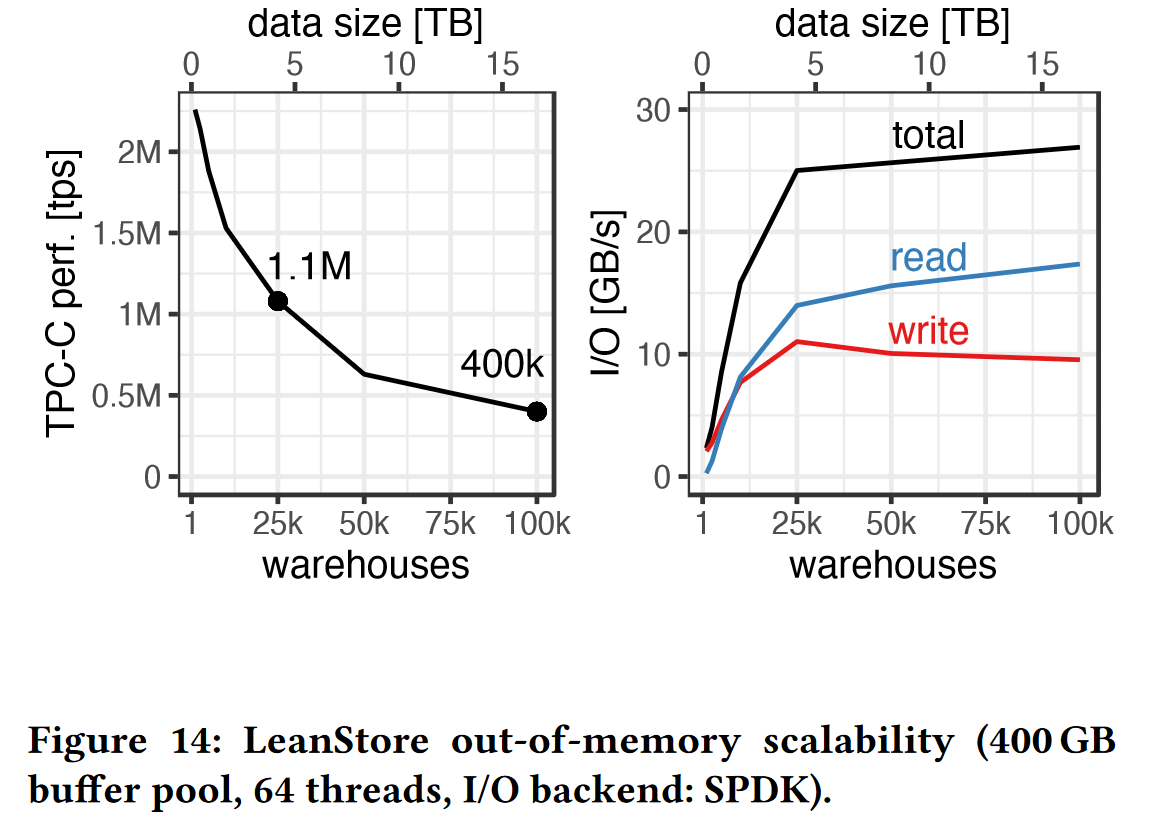
- 实验3:性能测试,随着数据集(仓库数量)的增加,事务吞吐量和带宽的变化
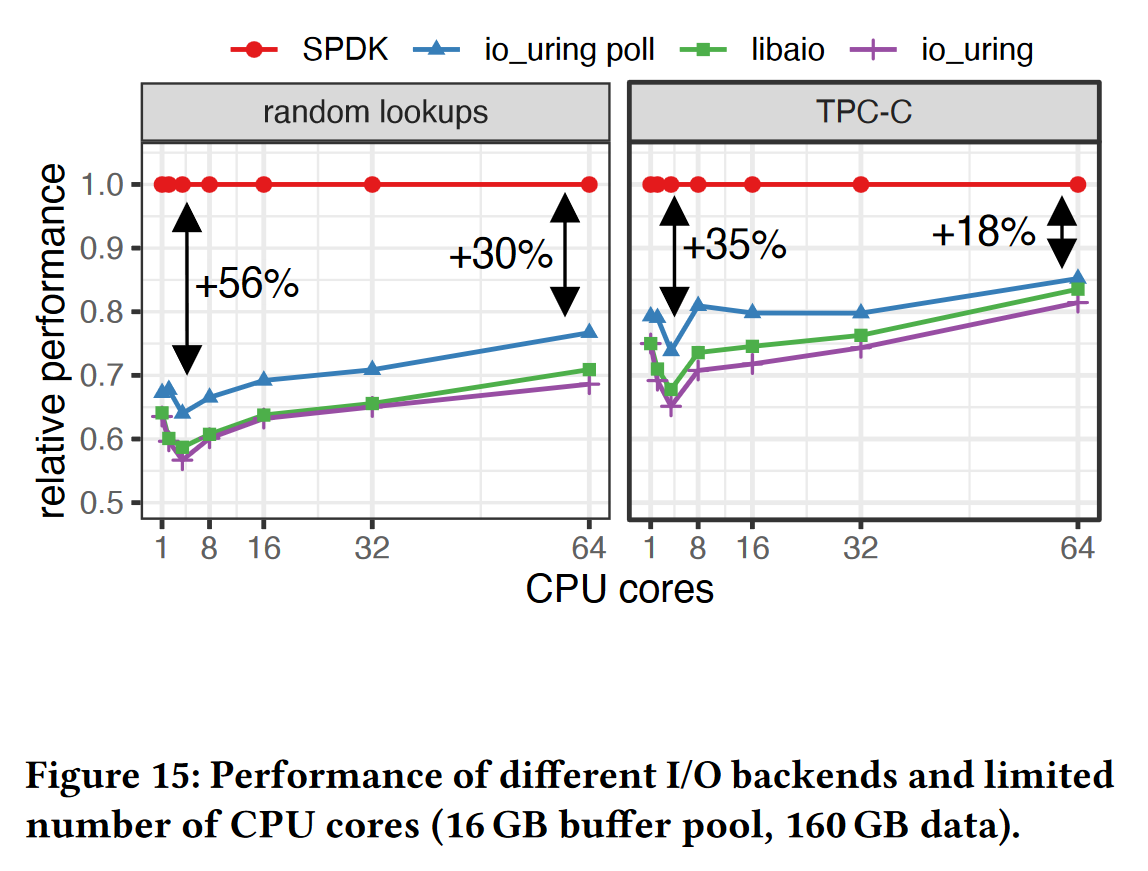
- 实验4:实现了多种不同异步I/O接口,比较它们在CPU核数增加时的性能影响
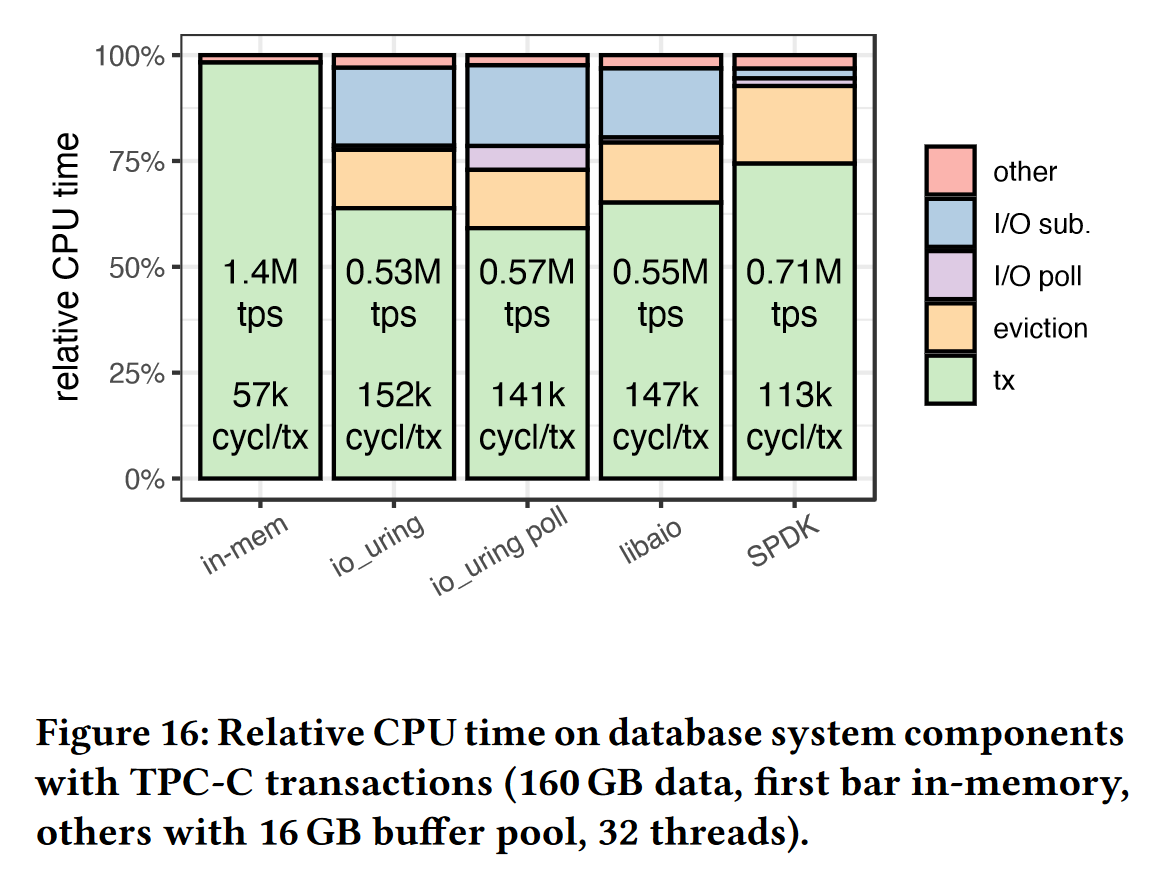
- 实验5:对比不同异步I/O接口的 CPU 利用率
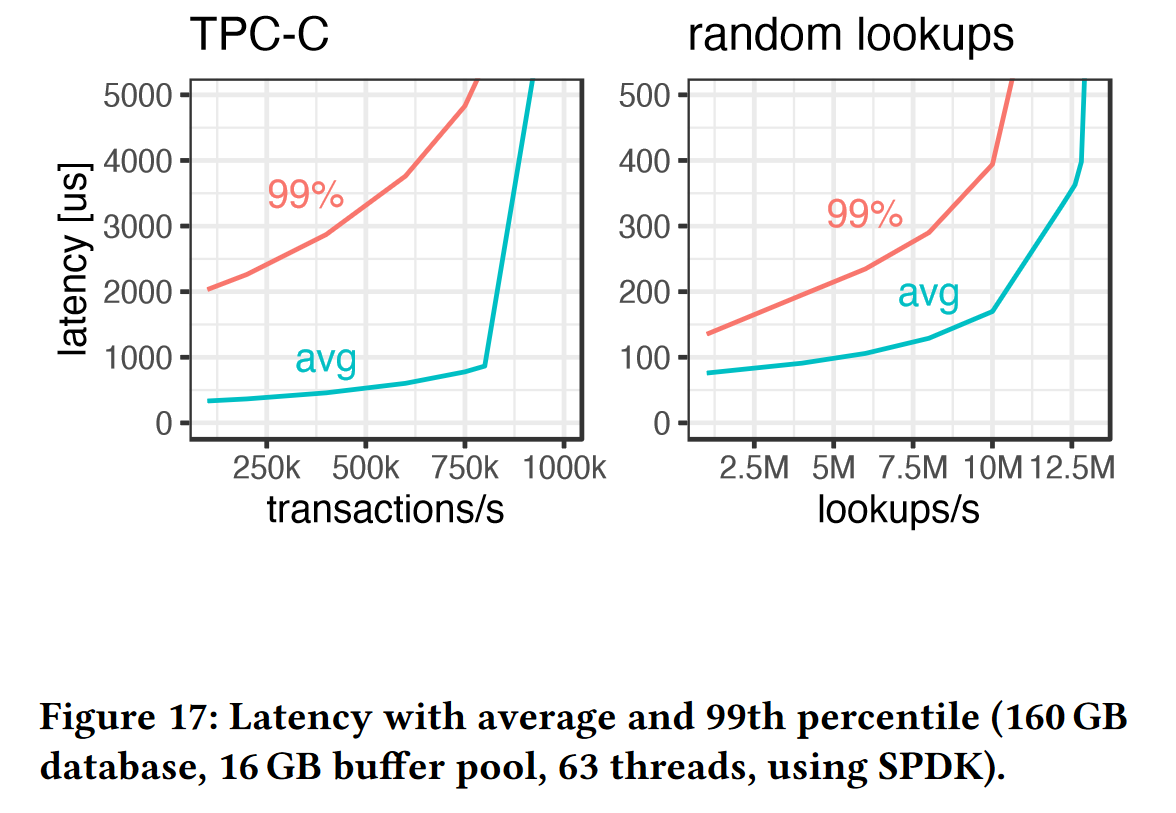
- 实验6:测量事务延迟,在 TPC-C 负载下,由于每个事务平均需要4个同步读操作和3个页面写入,这导致了更高的读尾延迟,因为它们会被写操作暂停
总结
本篇文章最大的贡献在于做了很多对比实验,对TP数据库的存储引擎设计与优化提供了很多参考性的建议
1、一些重要概念:
- 闪存SSD, 普通SSD
- PCIe/NVMe接口,SATA接口
2、关于 O_direct,直接io,即非缓冲io
为什么有的系统需要内核缓冲io,有的系统需要直接io?
- 文件系统,网络服务等需要内核缓冲io(不加io_direct),由于内核缓冲区可以减少磁盘IO的次数,相当于利用了数据的局部性;
- 数据库等应用需要 io_direct,数据库需要自己的内存缓冲区管理数据,不经过内核缓冲区可以减少数据复制的次数,提高性能。
leanstore 运行 spdk
1 | |