A Critique of ANSI SQL Isolation Levels 论文笔记
A Critique of ANSI SQL Isolation Levels 经典论文
2.1、基本定义
history:将多个事务的多个操作交替执行的序列建模为一个线性的执行顺序,如 R1,W2,R2,W1
conflict:两个事务操作同一个data item,且其中一个是写操作
data item:可能是表的一个元组,一个逻辑页面,或一个完整的关系表,或队列中的消息等
dependency graph:依赖图,图中每个节点代表事务的一个操作,若 T1 事务的 op1 在 T2 事务的 op2 之前发生,并且这两个发生了冲突,那么在依赖图中可以用 <op1,op2> 代表 op1 和 op2 节点之间的边;
两个history是等价的情况:有相同的已提交的事务集合,并且依赖图相同;
定义 history 是否可以串行化:若一个普通的 history(事务操作相互重叠,如 R1,W2,R2,W1) 能和另一个串行执行事务的 history (事务顺序执行,如:R1,W1,W2,R2 先事务1后事务2)等价,说明该 history 可串行化;
2.2 ANSI SQL 的隔离级别
P0 脏写(Dirty Write):有写锁,但写完立刻释放
导致的问题:T2 事务覆盖了另一个在运行中、尚未提交事务 T1 写入的值
比如约束条件: x == y,init:x = y = 0
| T1 | T2 |
|---|---|
| write x = 1 | |
| write x =2 | |
| write y = 2 | |
| write x= 1 |
但最终结果,x = 1,y = 2 违反了一开始的一致性约束
P1 脏读(Dirty Read):读到了一个尚未提交的事务修改的值,那个事务在修改后发生了rollback,导致本事务脏读
狭义脏读:w1[x]…r2[x]…(a1 and c2 in either order)
| 事务 T1 | 事务 T2 |
|---|---|
| begin (a=1) | begin (a=1) |
| write a=2 | |
| read a==2 | |
| rollback | |
| read a==1 (前后两次 read 不一致) |
广义脏读:w1[x]…r2[x]…((c1 or a1) and (c2 or a2) in any order)
| 事务 T1 | 事务 T2 |
|---|---|
| read x=50 | |
| write x=10 | |
| read x=10 | |
| read y=50 | |
| commit | |
| read y=50 | |
| write y=90 | |
| commit |
事务 T1 将 x 转账 40 到 y 账户上,T2 也会造成脏读
P2 不可重复读(Non-repeatable):针对数据的修改,本事务分别两次读到了其他事务修改前和修改后的值
| 事务 T1 | 事务 T2 |
|---|---|
| begin (a=1) | begin (a=1) |
| read a=1 | |
| modify a=2 | |
| commit | |
| read a=2(前后两次 read 不一致) |
P3 幻读(Phantom):针对数据的插入或删除,本事务分别两次读到了其他事务修改前后值的数量不同
| 事务 T1 | 事务 T2 |
|---|---|
| begin | begin |
| select count(*) from student (50) | |
| insert into student a tuple | |
| select count(*) from student (51) |
P4 丢失修改(lost update):两个事务同时对一个数据项进行更改,一个先提交,一个后提交,后提交的事务修改将覆盖前一个提交事务的修改
| 事务 T1 | 事务 T2 |
|---|---|
| read x=10 | |
| read x=10 | |
| write x=12 | |
| commit | |
| write x=13 | |
| commit | (T2 的修改无效了) |
Cursor Stability:可以防止丢失修改异常
在RC(read commited)基础上,在游标打开后进行加锁,其他事务可以读取打开的游标的数据,但不能修改这些在游标控制范围内的数据项
P5 读偏斜(Read Skew)与写偏斜(Write Skew)
读偏斜:读到了数据一致性被破坏了的数据,比如数据的约束条件是 X + Y = 100,但事务并发过程中,其中某个阶段一个事务读到了 X + Y =120,就会破坏了事务的一致性
| 事务 T1 | 事务 T2 | X | Y |
|---|---|---|---|
| Read X=50 | Read X=50 | 50 | 50 |
| write X=30 | 30 | 50 | |
| write Y=70 | 30 | 70 | |
| Read Y=70 | 30 | 70 |
在事务 T2 看来,X + Y = 120,违反了事务的一致性
写偏斜:两个并发事务首先都读到了相同的数据集,然后各自分别修改了不同的部分,造成最后数据的一致性约束被破坏
比如数据的一致性约束是 X + Y <= 100
| 事务 T1 | 事务 T2 | X | Y |
|---|---|---|---|
| Read X=10 Y=20 | Read X=10 Y=20 | 10 | 20 |
| write X=70 | 70 | 20 | |
| commit | 70 | 20 | |
| Write Y=50 | 70 | 50 | |
| commit | 70 | 50 |
在最后的数据结果中,X + Y > 100,违法了一致性约束
一些缩写:
w1[x]:事务1写数据项x
r2[x]:事务2读数据项x
r1[P]:事务1读符合条件 P 的所有数据项
w1[P]:事务1写符合条件 P 的所有数据项
c1:事务1进行 commit
a1:事务1进行 abort 或 rollback
根据上面的三种现象,可以分别进行形式化表达:(严格定义)
A1脏读:w1[x] . . . r2[x] . . . (c1 or a1)
A2 不可重复读:r1[x]…w2[x]…c2…r1[x]…c1
A3 幻读:r1[P]…w2[y in P]…c2…r1[P]…c1
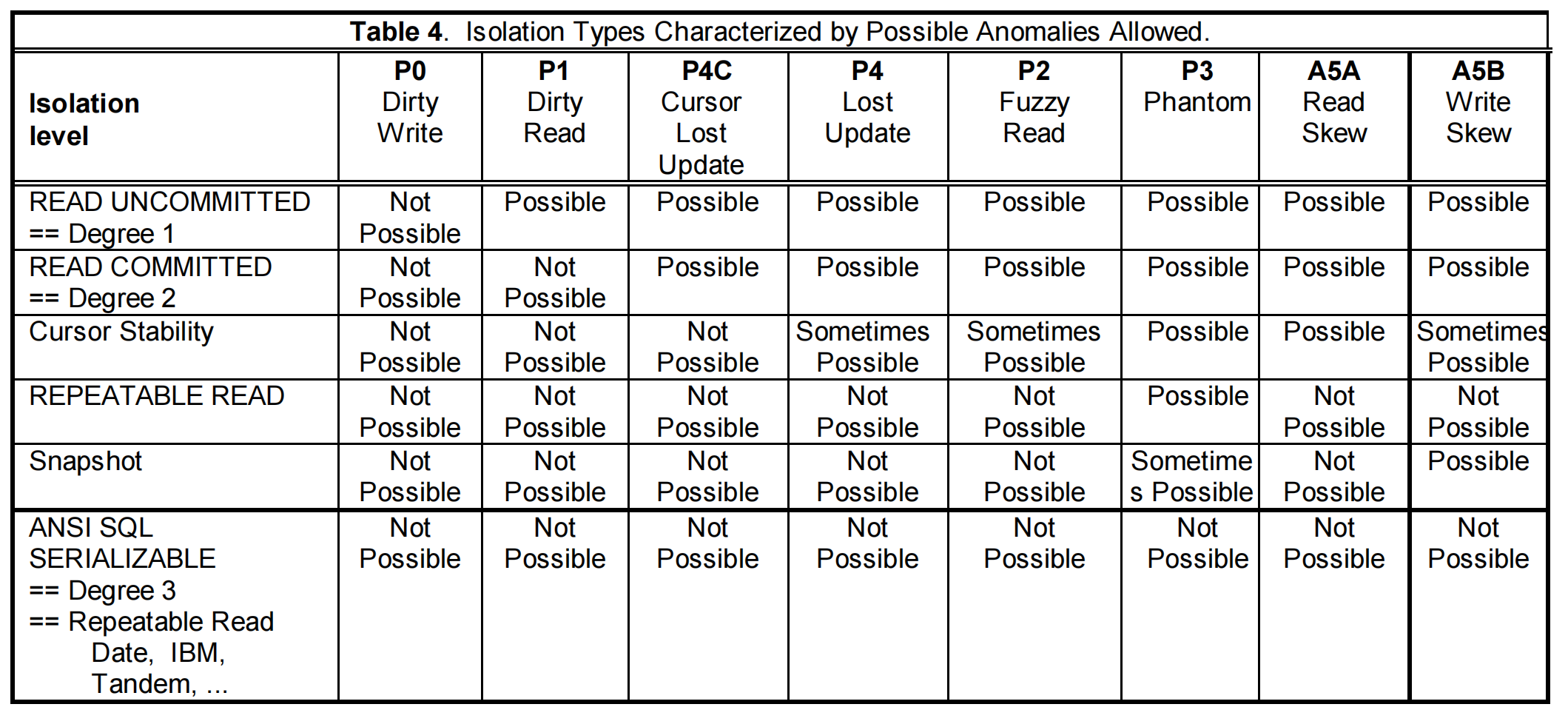
在 ANSI 中定义了四种隔离级别和与之对应的三种情形:(打勾代表会出现的问题)
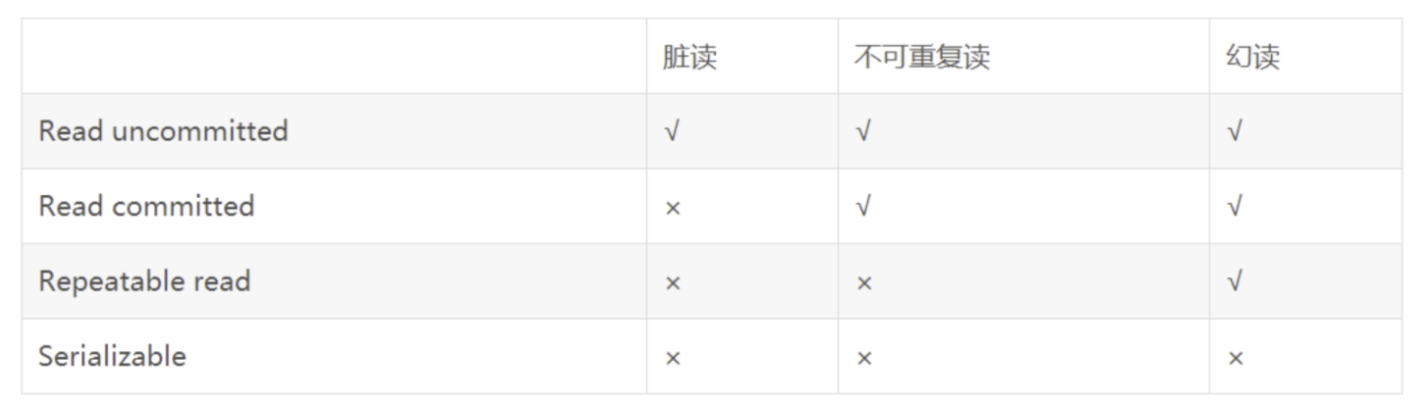
- RU:读未提交(读不上锁;写的时候上锁,并只在事务提交或回滚才释放)
- RC:读已提交(读上锁,读完立刻释放;写的时候上锁,并只在事务提交或回滚才释放)
- RR:可重复读
- Serializable:可串行化
4.2 Snapshot Isolation
快照隔离:一种多版本并发控制隔离
1、每个事务在 begin 时创建一个开始时间戳,该事务自此以后所有的操作(读取写入)都基于这个快照版本,其他事务在这期间对相同数据项的修改,此事务不可见
2、当事务 T1 准备提交,它会获得一个 commit 时间戳,当前 T1 能够成功提交的充要条件:不存在其他事务 T2 的 commit 时间戳在 T1 的执行时间内(即 [ start-timestamp, commit-timestamp ] ),否则 T1 rollback,这是为了防止丢失修改错误
(谁先 commit,谁先成功)
如果一个事务在另一个事务进行了更新并提交后才试图读取相同的数据,那么它将看到更新后的数据,而不是原始数据。这可以防止脏读(Dirty Read)和不可重复读(Non-Repeatable Read)等并发问题
| T1 | T2 |
|---|---|
| begin | begin |
| read x0=50 | |
| write x1=10 | |
| read x0=50(读到的是begin的快照) | |
| read y0=50 | |
| commit | |
| read y0=50 | |
| write y1=90 | |
| commit |
| T1 | T2 |
|---|---|
| begin | begin |
| read x=50 | |
| read y=50 | |
| read x=50 | |
| read y=50 | |
| write y=-40 | |
| write x=-40 | |
| commit | |
| commit |
狭义上的幻读 A3
A3: r1[P]…w2[y in P]…c2…r1[P]…c1
| T1 | T2 |
|---|---|
| begin | begin |
| select count(*) from student (50) | |
| insert into student a tuple | |
| commit | |
| select count(*) from student (51) | |
| commit |
广义上的幻读 P3
P3: r1[P]…w2[y in P]…((c1 or a1) and (c2 or a2) any order)
隔离级别的总结
读未提交(RU):顾名思义,其他事务读到了当前事务没提交的修改
| T1 | T2 |
|---|---|
| begin (a=1) | begin (a=1) |
| write a=2 | |
| read a==2 |
读已提交(RC):会读到其他事务已提交的数据,造成不可重复读
| T1 | T2 |
|---|---|
| begin | begin |
| select * from user;(1,a) | select * from user;(1,a) |
| update user set name =’b’ where id=1; | |
| select * from user;(1,b) | |
| select * from user;(1,a) | |
| commit | |
| select * from user;(1,b) | |
| commit |
可重复读:读不到其他事务已提交的数据
| T1 | T2 |
|---|---|
| begin | begin |
| select * from user;(1,a) | select * from user;(1,a) |
| update user set name =’b’ where id=1; | |
| select * from user;(1,b) | |
| select * from user;(1,a) | |
| commit | |
| select * from user;(1,a) | |
| commit |
特殊:并发写的例子:
| T1 | T2 |
|---|---|
| begin | begin |
| select * from user;(1,a) | select * from user;(1,a) |
| update user set name =’b’ where id=1; | |
| select * from user;(1,b) | |
| select * from user;(1,a) | |
| update user set name =’c’ where id=1; | |
| 等待.. T1commit后这条update语句才执行 | |
| commit | wait |
| update执行成功(1,c) | |
| commit |
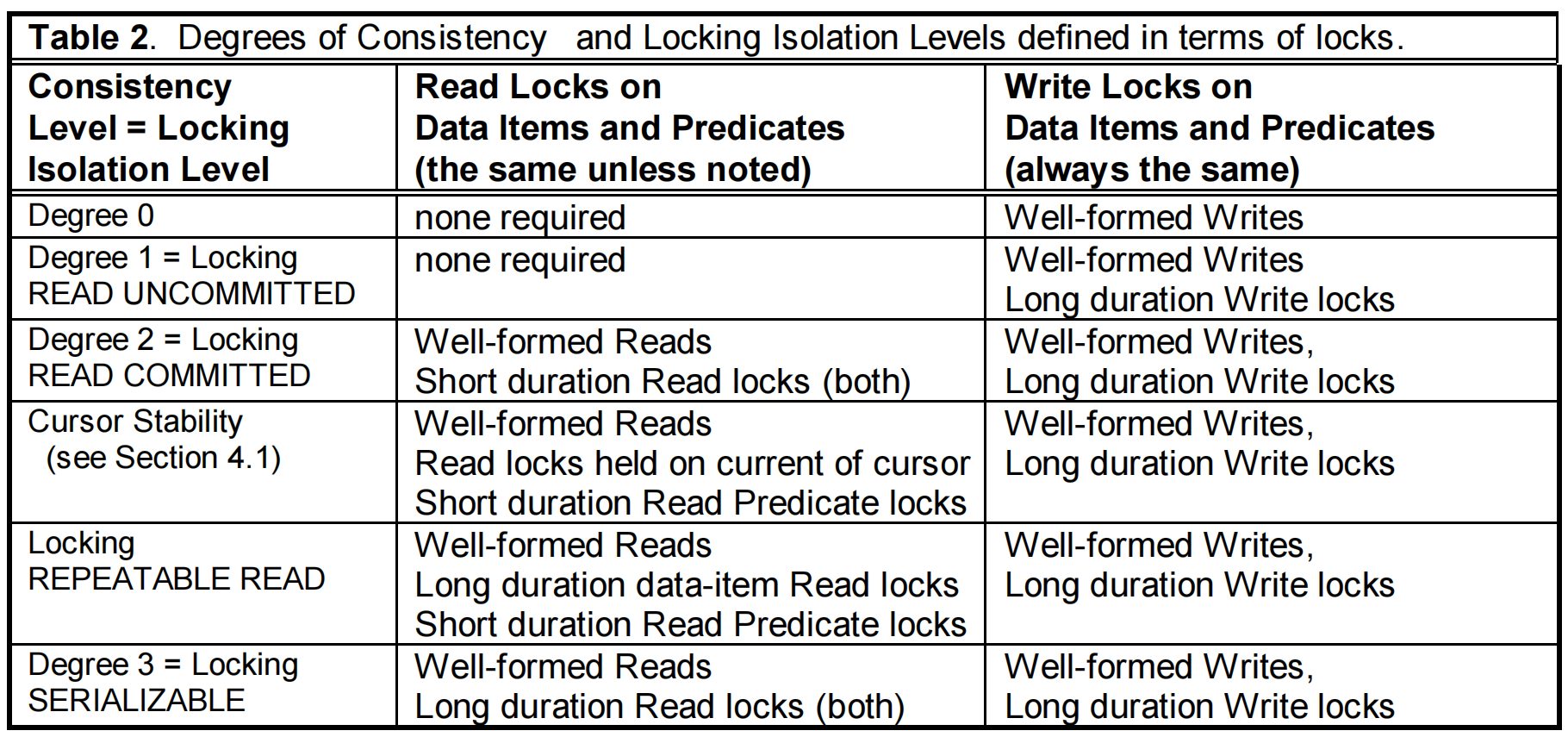
表2 根据读锁、写锁定义一致性的程度和隔离级别
degree 0:只需要保证每个操作是原子性的,读不上锁,写操作加锁写完立刻释放;
degree 1:读未提交,读不上锁,写锁仅在事务 commit 或 rollback 释放,可以防止上一级的 dirty write 异常,但可能会读到其他未提交事务的更改,即脏读(dirty read);
degree 2:读已提交,读上读锁,读完立即释放,写锁仅在事务 commit 或 rollback 释放,可以避免读到其他事务未提交的数据,但当别的事务提交后,可以读到新的数据,由于与之前读到的不一致,可能造成不可重复读(Fuzzy Read)和丢失修改(lost update);
Cursor Stability 级别:用于在RC基础上防止丢失修改(后一个事务对相同数据的更新提交覆盖前一个事务的提交),方法是读数据时在游标打开后进行加读锁,其他事务可以读取打开的游标的数据,但不能修改这些在游标控制范围内的数据项;
可重复读:在当前事务过程中,读不到其他事务提交的更改
快照隔离:每个事务开始时获取一个快照,之后的读写都从这个私有快照中获取数据
可重复读和快照隔离的区别:
可重复读通过对数据项加长时间读锁来防止丢失修改和不可重复读
快照隔离通过采用多版本数据项形式防止不可重复读
degree 3 串行化:事务可串行化