LSM-Tree 笔记
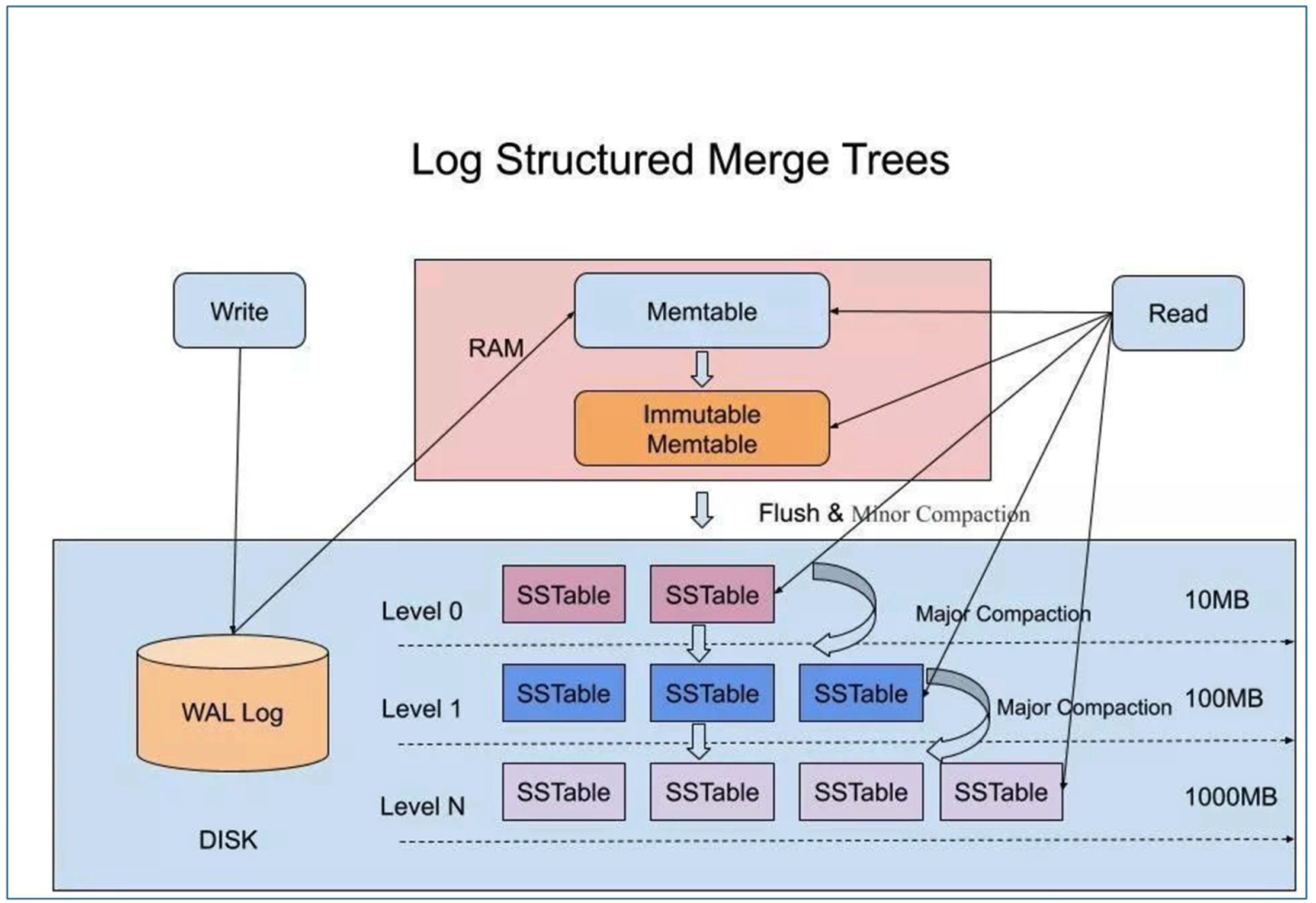
LSM-Tree ( log structured merged tree )
1 在 OLTP 里数据存储分为两种:
- 面向页的存储引擎:innodb(B+ tree)
- 面向日志结构的存储引擎:leveldb(lsm tree)
2 LSM-Tree 用于解决什么问题?用在什么场景?
写多读少的场景
海量数据存储
日志系统
推荐系统
- 数据需要大量写入
- 存在少部分读数据的场景,但大部分情况对读的实时性要求较低
3 LSM-Tree 如何解决大量写?
利用顺序IO,即追加写的方式,将用户的所有修改操作(insert,update,delete)采用追加的方式记录在磁盘中,类似于打印日志的方式。
优点:顺序IO,使写性能提高;
缺点:空间放大,同一份数据的各种修改操作分在了不同的块中,存在过时的数据修改记录;
解决方法:后台定期压缩和合并数据,消除无效数据;
3.1 LSM-Tree 如何提升合并的效率?
当每个文件写入的数据有序时,可以利用多路归并的思想合并;
合并的方式:
- 分级合并:leveling
- 分层合并:tiring
如何保证每个文件写入的数据有序:
- 先在内存中缓存数据,并将数据排好序,异步刷入磁盘,保证了每个磁盘文件内部数据有序
需要首先保证内存中的数据有序:
- 跳表,B+树,红黑树
如何保证在内存中缓存的数据不丢失,进程挂掉了,数据丢了咋办?(容错机制)
- WAL 写前记录的日志(redo 日志同理)
- 在所有写操作应用于状态机之前,写入redo log,顺序IO刷入磁盘,出故障后修复
3.2 内存中数据结构的选型
如何选择一个在各方面 trade-off 的数据结构,能高效维护内存数据的有序性,并发性?
来自 rocksdb 的解答:https://github.com/facebook/rocksdb/wiki/memtable
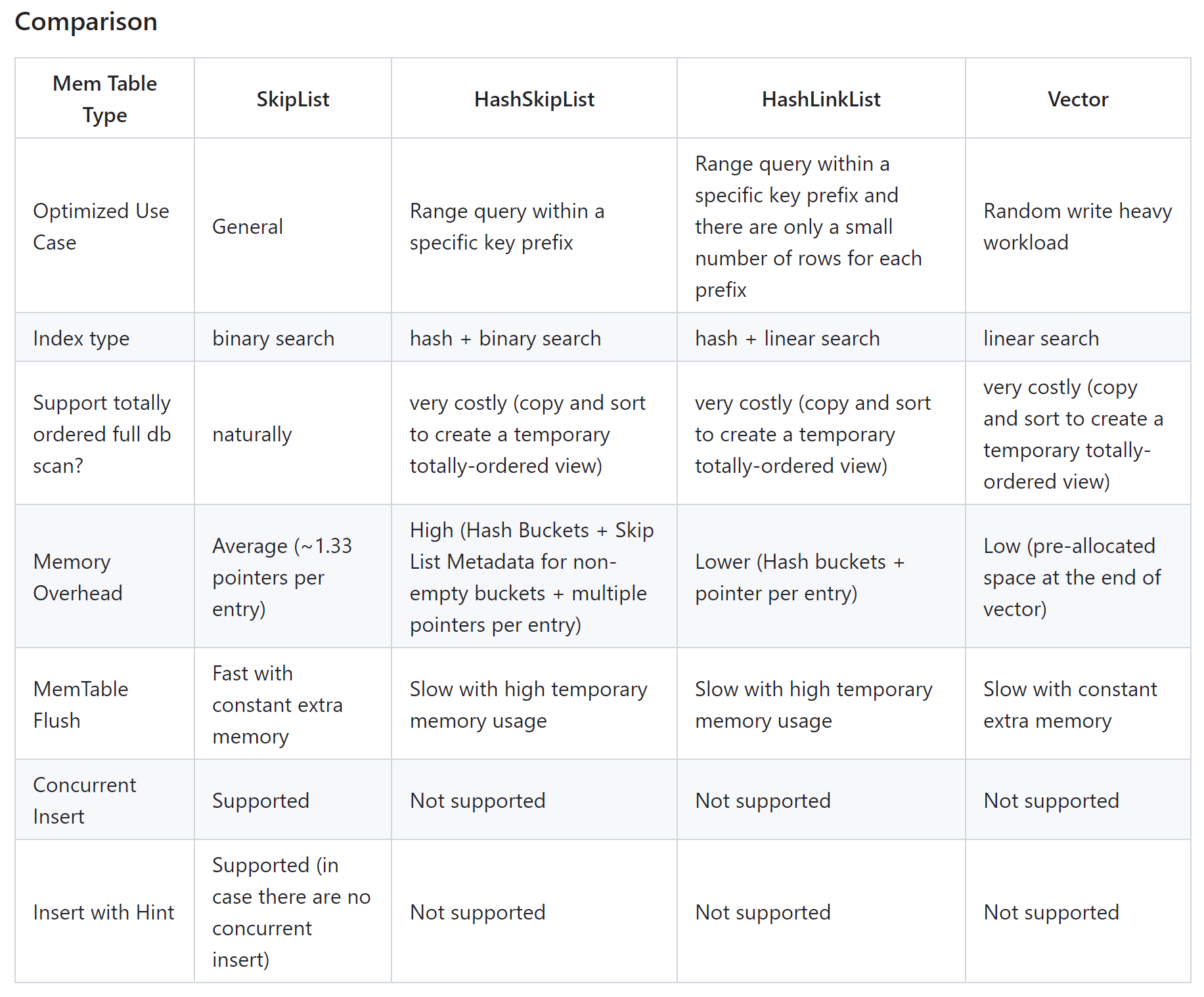
跳表、hash跳表、hash链表、数组
跳表能很好地支持并发插入,非常适用于大量写场景
3.3 大量写的总结
系统内部存在三种数据:
- 内存数据(memtable)需要满足有序性,比如:skiplist
- 磁盘数据(SSTable)
- 日志数据(redo log)也就是 mysql 里面的 WAL
数据压缩、合并等处理方式:
- 分层压缩
- 分级压缩
- 后台定时触发
- 后台达到阈值时触发
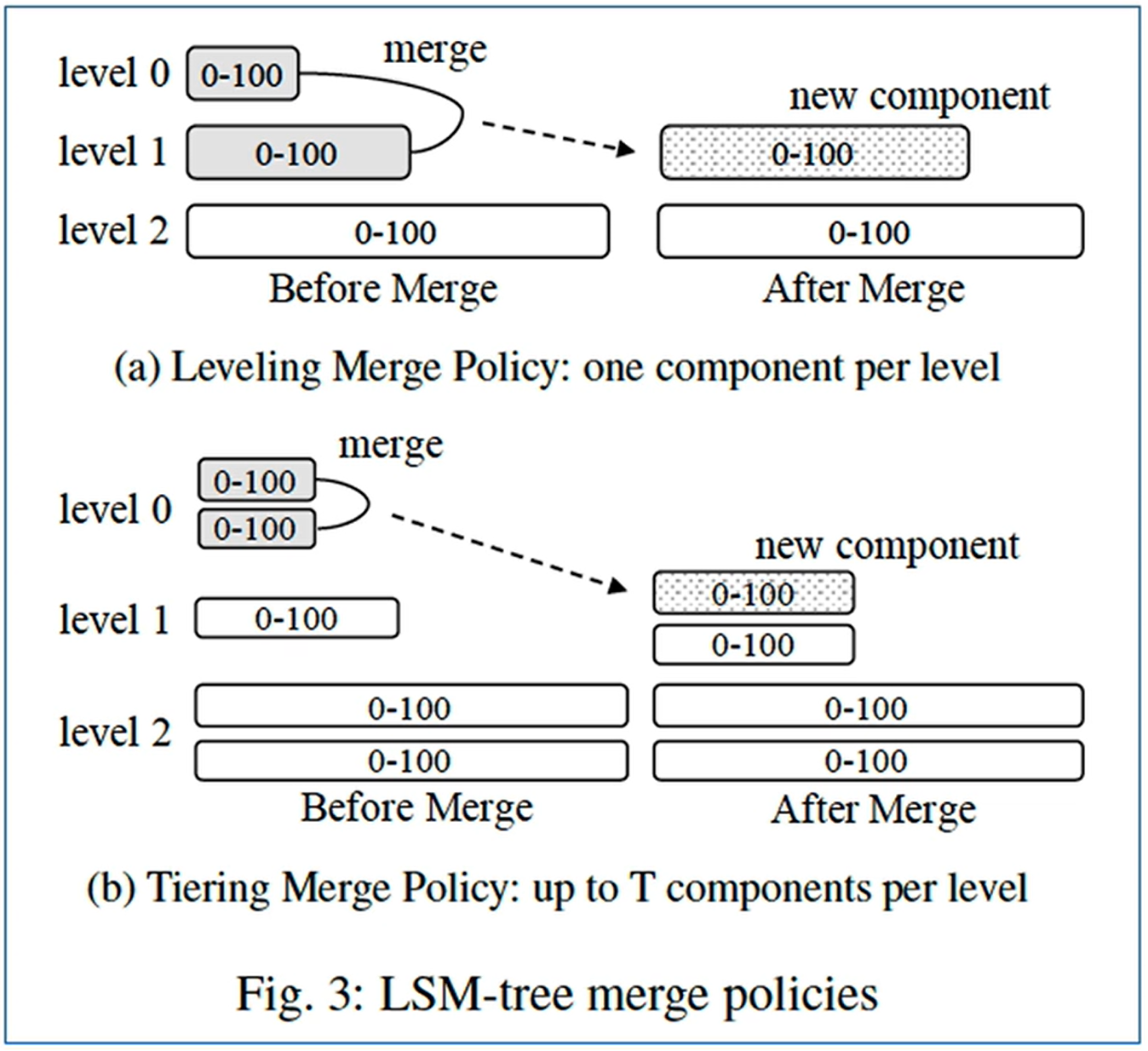
4 LSM-Tree 合并的策略
5 LSM-Tree 如何解决读数据?
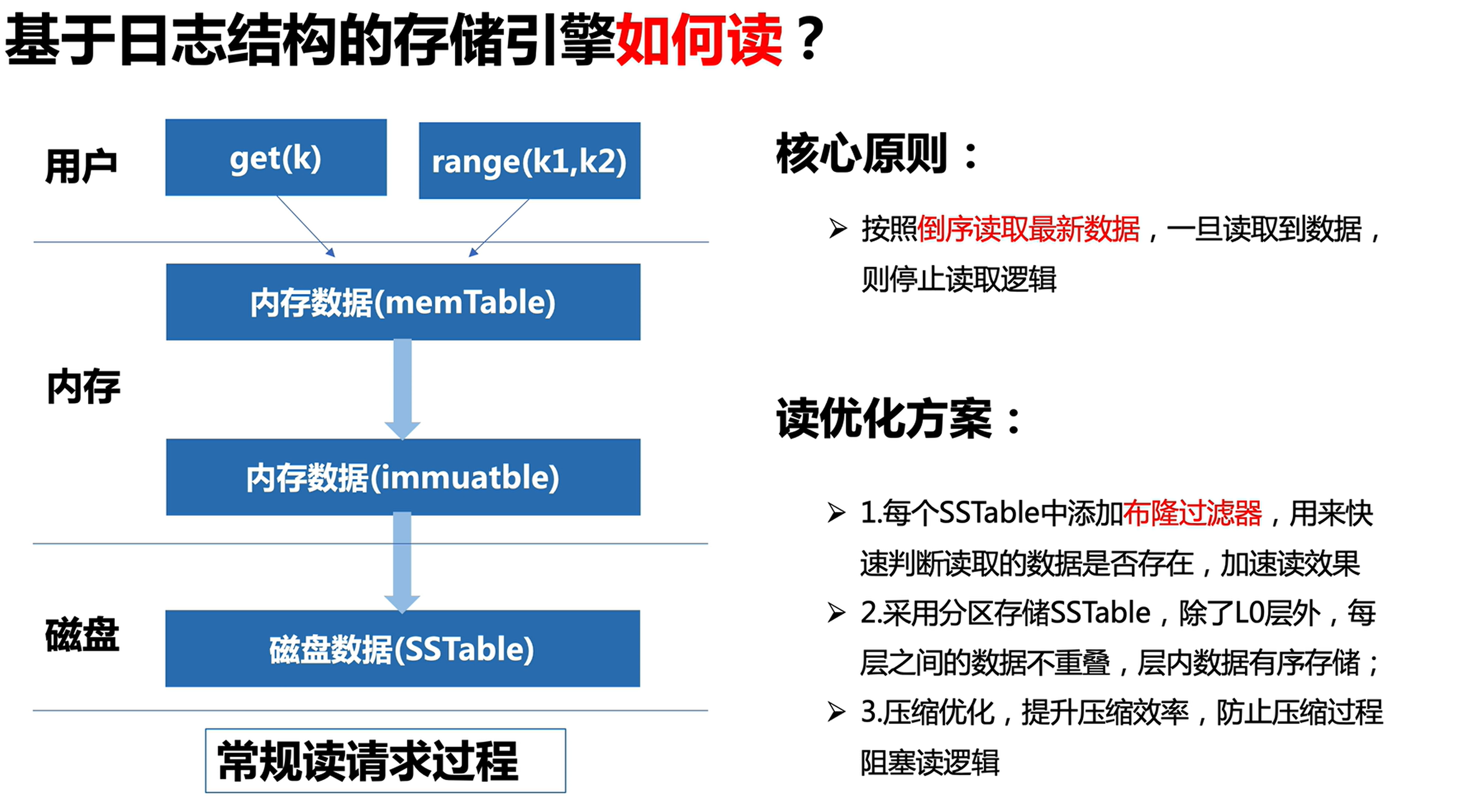
6 LSM-Tree 的三大问题
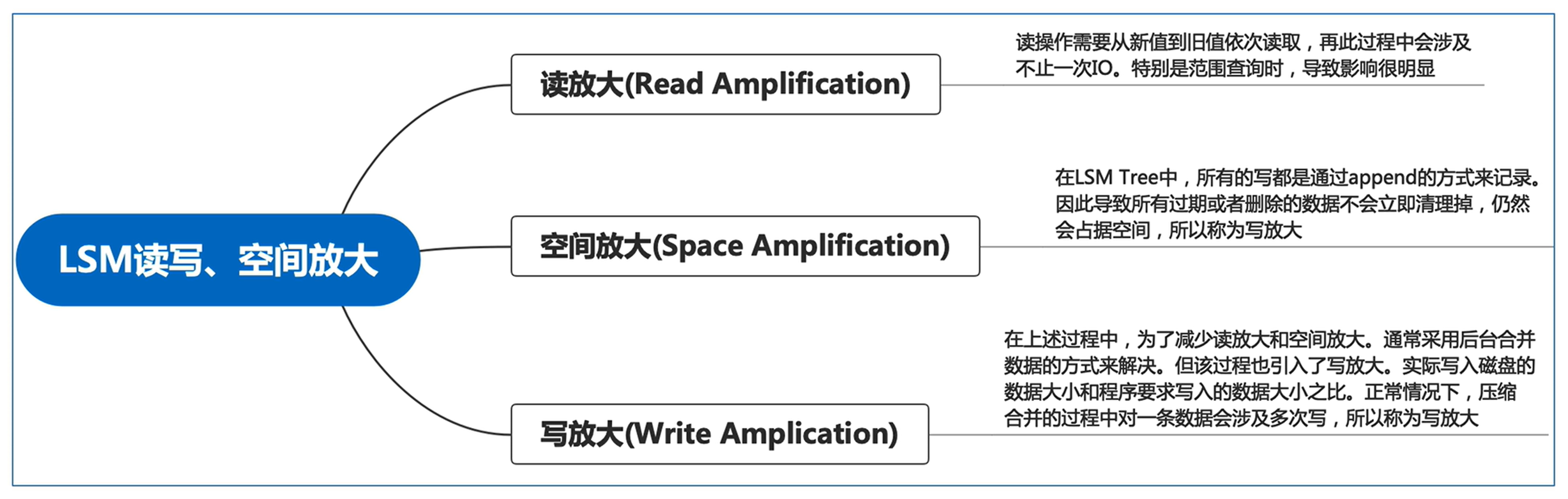
读放大
从最新数据往前读,一次读不止一次IO
空间放大
一个数据项可能涉及多个日志记录的操作,过期或删除的数据项不会立刻清除,造成空间浪费
写放大
在插入新数据时,频繁的合并和压缩操作导致磁盘的写入量非常大
合并操作:涉及大量的读数据、写数据
压缩操作:读取数据,重新组织,写入新数据
写放大不仅限制了LSM树的写入性能,而且会由于频繁的磁盘写入缩短 SSD 的寿命
详细解读 lsm-tree 的两个合并策略
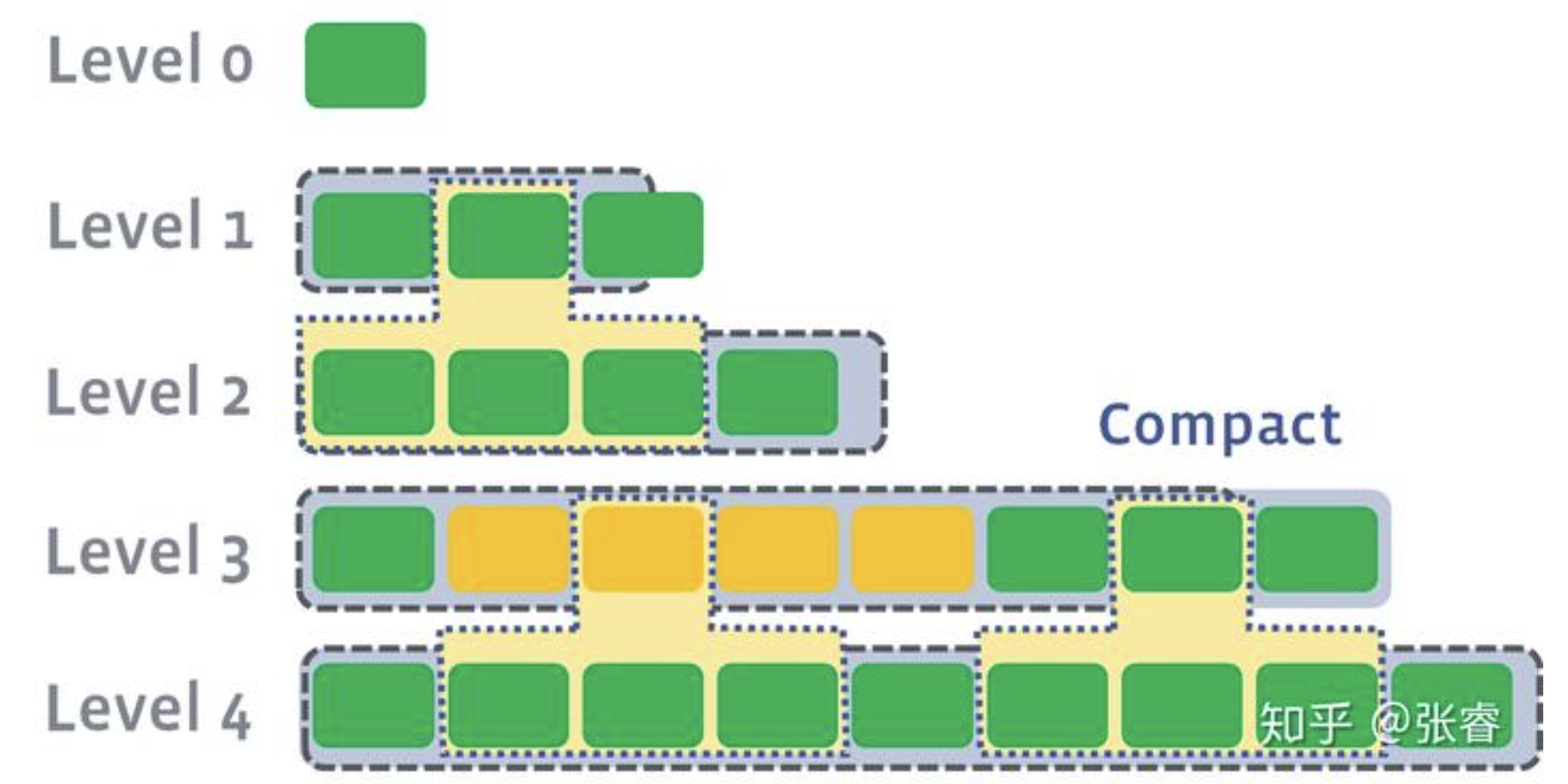
1、level compaction 分层合并
- 每个 level 维护多个基本相同大小的 SST
- 每个 SST 之间都是顺序有序的
- 比如第 i 层 SST1: 0
59,SST2:6089,SST3:90~99
- 比如第 i 层 SST1: 0
- 合并可以并行,第3层第3个合并到第4层2
4组件,同时第3层第7个合并到第4层68组件
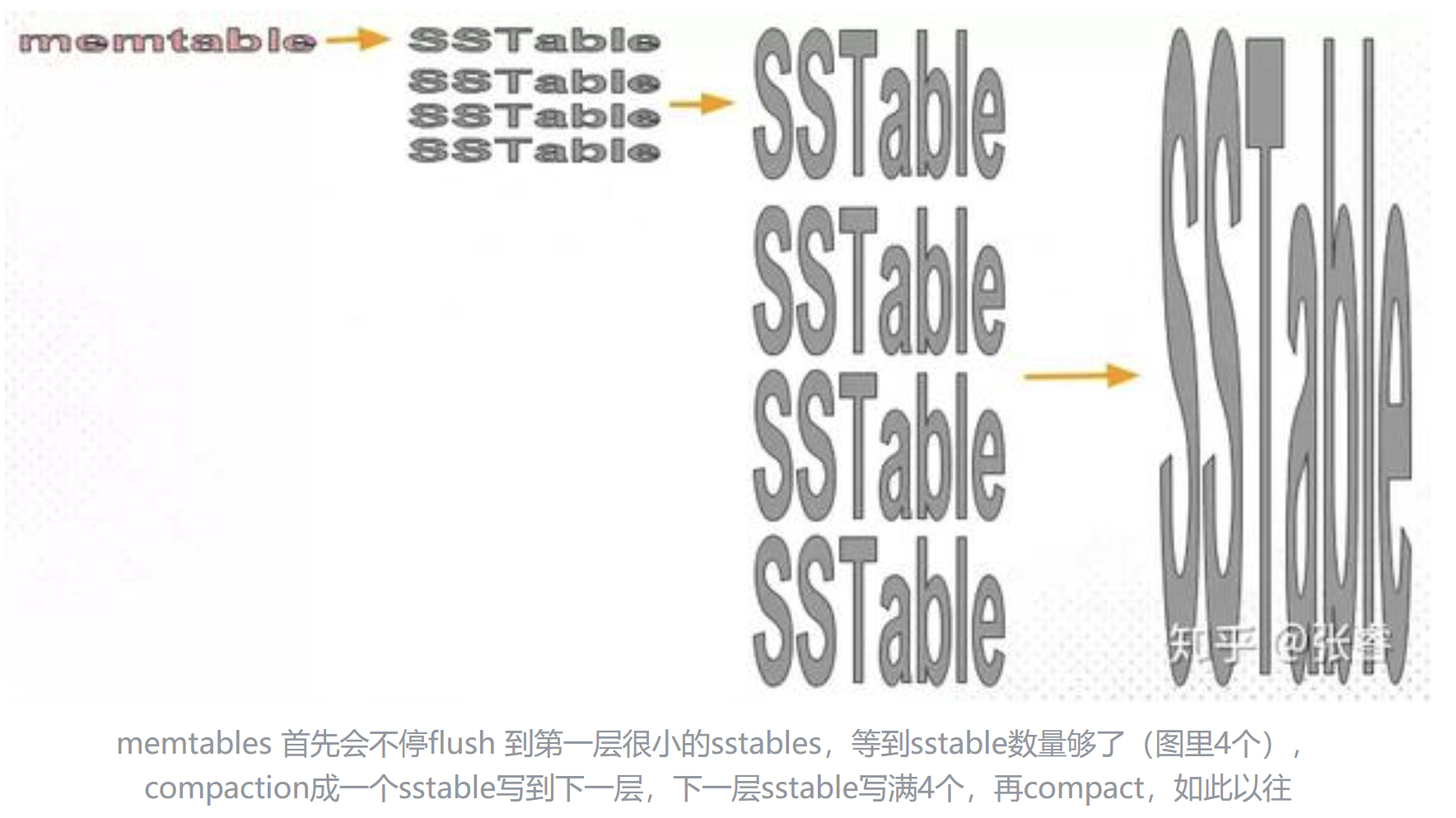
2、Tier compaction 分级合并
- 每层中,一个 SST 内部键值对有序,SST 之间键值对无序
- 若干个(4个)SST 合并到 i+1 层的一个新的 SST,新的 SST 与本层其他 SST 可能会有键值对重复
LSM-Tree 笔记
https://yanghy233.github.io/2024/04/16/lsm-tree/