HackWrench 细粒度分布式事务提交 (VLDB 23)
Fine-Grained Re-Execution for Efficient Batched Commit of Distributed Transactions (VLDB 23)
通过细粒度重新执行的方式实现分布式事务的高效提交
1 介绍
分布式OLTP系统通常需要横跨多个节点来提交一个可串行化的事务;
近10年来有很多分布式的OLTP被提出,包括 Spanner,CockroachDB,FoundationDB,虽然它们可以横向扩展到多个节点,但性能始终没有得到很好的优化。
分布式事务执行缓慢的原因:
- 数据是跨节点分布的,在事务执行过程中,系统需要远程抓取数据;
- 为了提交事务,系统还必须在多个节点之间协调,来确保可串行化;
- 执行和提交事务都需要节点间大量的往返阻塞式通信,这导致了吞吐量的降低和性能的下降;
Aurora 的优化
为了有效减少远程通信的数量,云数据库Aurora使用 caching 和 batching 显著提高了性能;
在计算节点上的缓存:在执行事务操作的时候可以减少对存储节点的远程读操作;
分批验证和提交:可以摊销多个事务之间的通信,从而减少每个事务的通信次数。打个比方,A事务涉及3个数据节点的通信,B,C事务也涉及这3个数据节点的通信,如果分别执行A,B,C事务,将产生至少9轮往返通信,但若这三个事务以一个批次执行,只需要3轮通信的往返,能够极大提高吞吐量;
但这两种方法仍存在缺陷,当事务之间存在的更多的关联性时,缓存和批处理会显著增加事务冲突的概率,从而引入大量事务回滚的性能开销:
若某个计算节点缓存了数据,当需要执行操作时,首先会从缓存中读取数据;
但如果其他节点同时提交了对相同数据的写操作时,那么该计算节点将会错过最新的数据;
在分布式事务的验证阶段,当存在一个事务对过时数据进行操作,将会因数据不一致而中止提交
同理,当多个事务被一起进行批处理验证时,如果发现存在一个事务是无效的,那么整个批处理的事务都得 rollback;
COCO 的优化
COCO是mit在vldb21提出来的一种事务提交策略,它以epoch为单位提交事务。通过对事务进行单独验证,并且只对验证通过的事务进行跨节点复制的方式来解决批处理性能较差的问题。这意味着每个事务都会单独进行验证,而不是一起批处理验证。只有验证通过的事务才会被收集起来,成批进行跨节点复制。这样做的好处是可以避免因为批处理中存在验证失败的事务而导致其他事务被迫中止的情况。
后面实验有本文作者提出的 Hackwrench 与 COCO 对比的实验
Hackwrench
本文提出的 Hackwrench,创新性地使用事务修复机制降低了缓存和批处理带来的分布式事务回滚开销。
核心思想:
通过应用最小修复措施,而非中止整个事务批次来提升缓存和批处理的性能;
事务的细粒度修复:通过重新执行被陈旧和无效读操作影响的操作修复;
为了支持细粒度修复的功能,Hackwrench 使用数据流图 dataflow graph 来清晰地表示事务操作之间的关联;
在提交阶段,Hackwrench 使用了分层提交协议,事务提交分为了本地提交和全局提交
- 本地提交使用2PL处理计算节点内部事务之间的冲突,并且节点内部使用的是RU隔离级别,事务可以读取本地提交事务的未全局提交的数据;
- 全局提交用于验证和提交一批本地节点已提交的事务组,类似2PC的工作原理,具体操作为:
- 准备阶段,计算节点与所有存储节点通信,验证事务的读操作,并在存储节点上持久化批处理中的写操作;
- 提交阶段,计算节点通知存储节点这批次事务的提交状态,各存储节点提交或回滚事务;
与传统2PC不同的是,Hackwrench 引入了两个变体:
1、当事务批次验证失败时候,计算节点将更新缓存,并利用更新后的缓存与事务之间的依赖关系进行事务的细粒度修复;(传统的2PC是直接该批次所有事务回滚)
2、Hackwrench 使用一个时间戳服务器来确定一批事务的提交顺序,修复事务时可以通过时间戳的顺序依次对事务进行修复;
one-shot 事务类型
- 普遍认为的分布式事务
事务里面的语句比如select,需要从多个不同的存储节点拿到数据;
即数据是分散存储的,一个select可能需要跨多个节点访问;
- one-shot 事务
来源于 VLDB08 的 H-Store,虽然一个事务不能在同一个节点上完成所有的执行,但事务里面的每条语句都能在一个存储节点上完成。
One-shot Transactions: A transaction is one-shot if it cannot execute on a single-site, but each of its individual queries will execute on just one site (not necessarily all the same site).
From H-Store —VLDB 08
对于 one-shot 事务的优化:
one-shot transaction:事务里面的每条语句都能在一个存储节点上完成,如果仍然通过分层提交协议提交将造成不必要的性能损失,Hackwrench 使用 fast-path optimization 方法将修复和提交的任务由存储节点直接完成,不依赖计算节点。
本文主要的贡献点
1、利用缓存和批处理降低远程节点通信次数,提高吞吐量;
2、提出分布式事务的分层提交协议,保证了事务先在本地节点可串行化,再在全局保证可串行化;
3、为了缓解过时缓存和批量提交冲突带来的事务回滚,Hackwrench 使用事务操作间的依赖和细粒度修改来修复无效或过时的读操作,降低了事务回滚的成本;
4、对一次性事务,提出了快速转发优化,直接在存储节点提交和修复,而不是计算节点,降低了整个系统远程节点之间的通信往返次数和2PC带来的开销;
5、在对比实验中,显著好于 FoundationDB , COCO 等系统。
2 背景和动机
2.1 影响分布式OLTP事务吞吐量和性能的两个重要原因:
- 跨节点通信
- 节点之间的远程同步
2.2 缓存与批处理在存算分离系统中的优点与挑战
在一般的存算分离系统中,开始执行事务时,计算节点首先会读取存储节点的数据,并将修改保存在自己的本地缓存;在提交事务的时候,计算节点首先需要与存储节点通信以验证本地的事务提交是没有冲突的。
Caching 机制:计算节点维护一个本地的缓存用于存储最近读取到的数据项,当只存在一个计算节点时,比如 single-master Aurora,这个缓存永远是一致的和最新的;但当存在多个计算节点时,每个计算节点的事务都可能对同一个存储节点的数据进行更改,这就会造成缓存的过时和无效。为了保证这种情况下事务的正确性,在事务的提交验证阶段就需要对数据项所在的存储节点进行检查,如果存在冲突,事务就需要回滚,比如 Sinfonia 系统,这就导致了事务处理的性能下降。
Batching 机制:事务的批量提交可以让存算分离系统尽可能地减少跨界点通信,但计算节点需要在存储节点上验证事务的读操作的正确性,如果某一个事务失败,将导致整一批事务的回滚,性能也会下降。
表1描述了缓存机制和批处理机制在分布式事务的性能表现:
p表示 分布式新订单事务的占比,它的百分比可以代表跨多节点事务的冲突程度;
在只有其他事务时,缓存和批处理策略能让吞吐量有近乎几倍的提升,而在单计算节点的多个不同批次间读未提交的数据时,吞吐量是巨大的;
但随着多仓库新订单事务的占比增加,所有的方法吞吐量都呈现下滑的趋势,下滑最明显的是batching策略,由于冲突的增加,无效的单个事务在批处理中增加,导致整一批事务都需要回滚,性能也在下滑
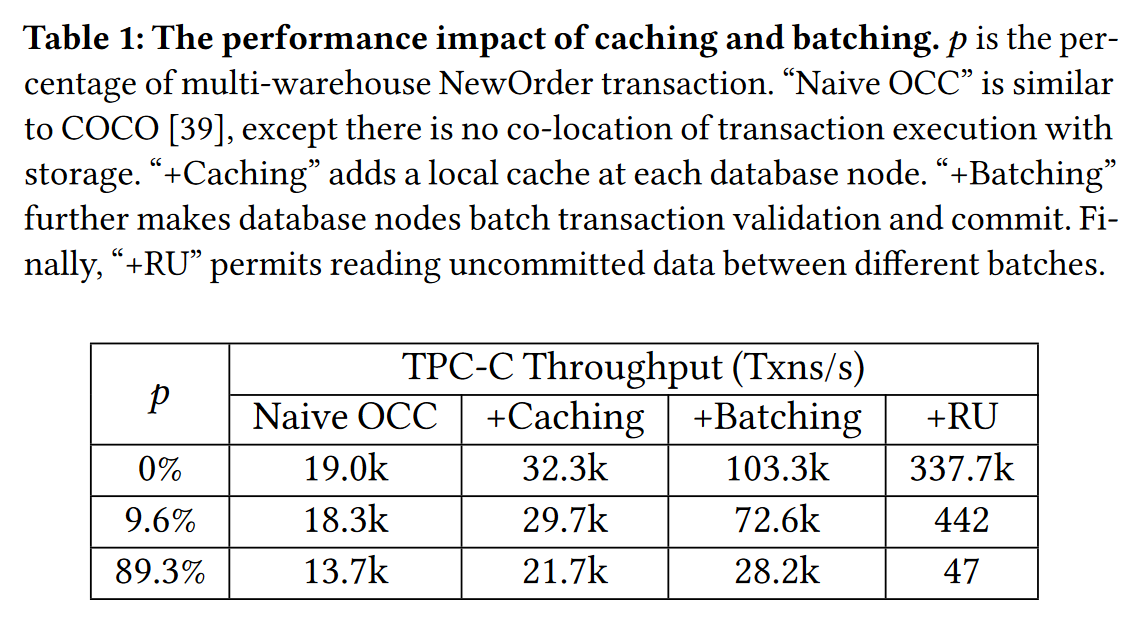
作者从这个实验得出的结论:
在低竞争程度时,尽可能保持有 RU 的性能;
在中或高竞争程度时,使用缓存和批处理方式外加一定的细粒度修复机制可以让分布式事务系统有更高的吞吐量。
2.3 提出的方法
分层提交策略
细粒度重新执行读操作修复无效的事务
图1用来说明细粒度修复的主要思想:
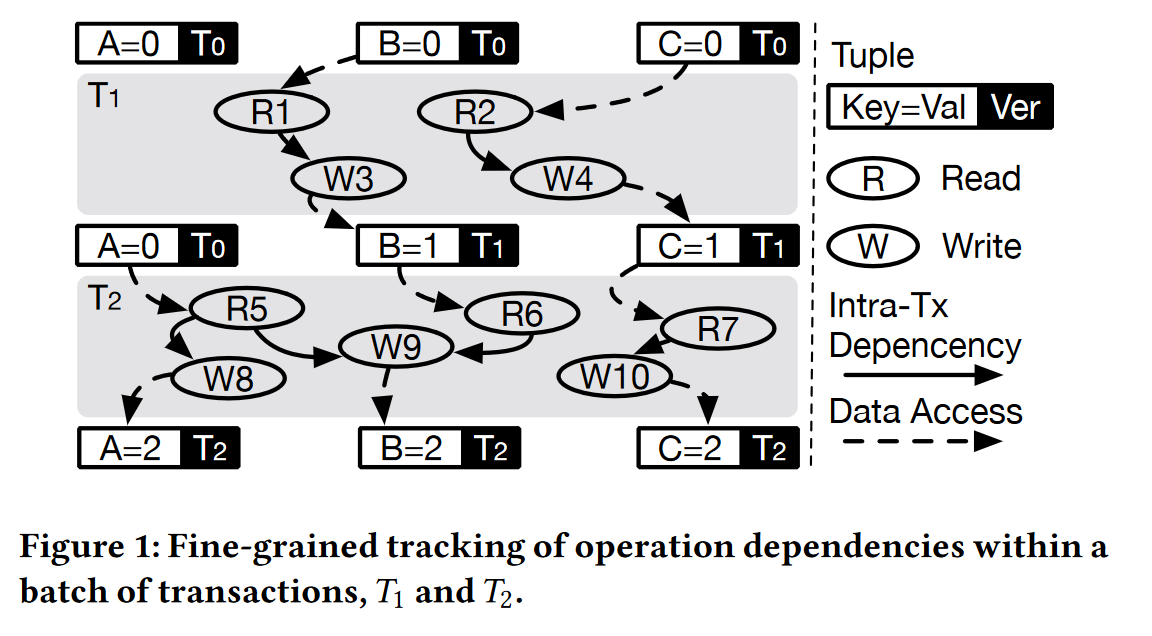
在批处理执行事务的过程中,系统会生成 dataflow graph;
事务操作之间是有隐藏的版本依赖关系,比如图中T1,T2的两个依赖关系:
W3 -> R6,W4 -> R7
在全局提交的阶段中,批处理的事务会首先在所有存储节点进行验证,当发现因为冲突或过时的缓存导致某些读操作读取的版本是过时的,此时借助数据流图中的依赖关系,可以精确定位需要重新执行的操作子集,将它们重新执行即可得到修复后的事务操作;
再以图1举例,假定在全局验证阶段发现原本 T0版本的数据C 已经被 T4事务修改成最新的,此时,只需要重做 R2, W4, R7, W10 即可进行细粒度修复,而无需对完整的一批事务(T1,T2)所有操作进行回滚重试。
3 Hackwrench 设计
3.0 系统架构图
Hackwrench 由多个计算节点 DatabaseNode 和多个存储节点 StorageNode 组成,计算节点负责执行事务和协调分层提交,存储节点负责存储数据和验证分布式事务,
同时维护一个时间戳服务器,用于确定全局事务批次的提交顺序:
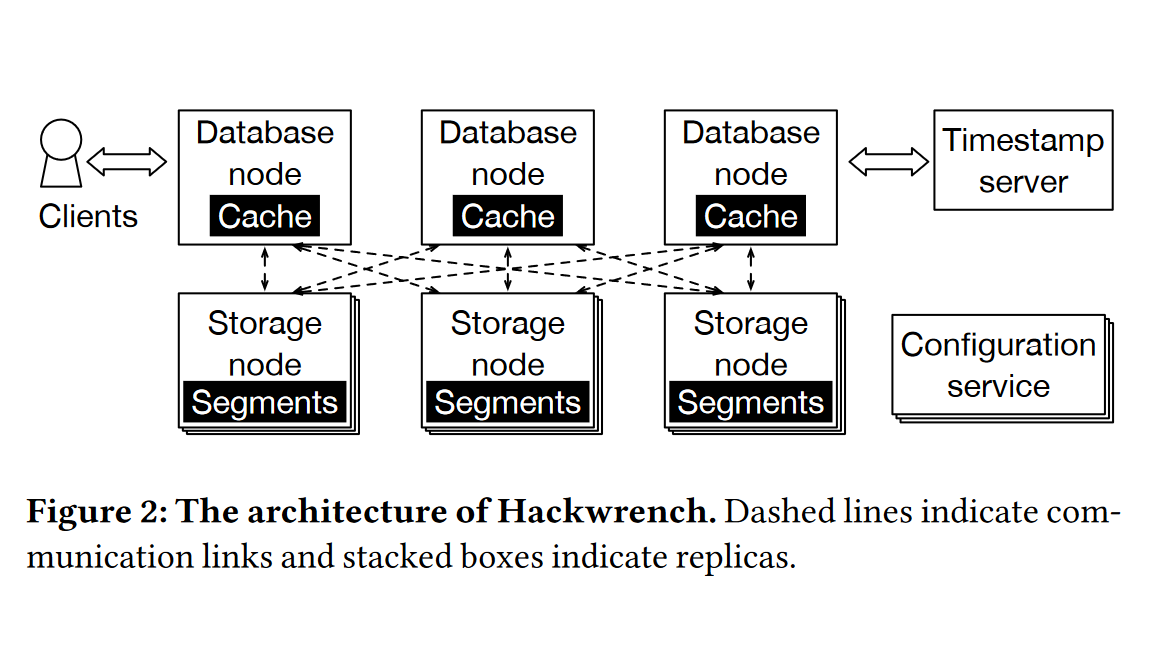
Hackwrench通过一个基于 paxos 的设置来维护系统各个节点的配置信息(视图),这个视图包括时间戳服务器的标识和数据段与逻辑存储节点的映射关系。
3.1 数据的组织方式
Hackwrench 将所有数据划分为数据段,每个数据段包含一批版本化的键值对元组;
每个数据段存储在一个逻辑节点上,配置服务器维护数据段与逻辑存储节点的映射关系;
每个元组的版本:<63位唯一标识符id,修复位>
其中,唯一标识符表示最后修改该元组的事务id,修复位用于确保重新执行的写与原来执行的不同;
每个计算节点维护一个元组级别的缓存,当发生 cache miss 时,将从远程存储节点读取元组缓存至本地,缓存每隔一定时间进行异步更新。
3.2 事务的执行和本地提交
- 关于事务的执行
在 Hackwrench 中,事务被描述成存储过程。在一般的OLTP系统中,存储过程通常用来进行性能的加速。
但在这里,Hackwrench 采用了基于数据流的编程抽象来描述存储过程;
基于设计的 dataflow API,用户提交的每个事务都能够清晰描述成一个数据流图;
并且我们为每个节点都复制一份事务的数据流图;
- 本地事务的提交
计算节点通过2PL的并发控制方法执行本地的事务批次,执行完成后,事务中的写操作会被应用到当前节点的缓存中,当前节点的其他事务都可见。
本地提交的事务将会追加到节点的本地队列中,等待批处理的全局提交。为了保证事务维持本地提交的顺序性,直到提交的事务被放入本地队列后,才释放2PL的锁。
3.3 全局提交
全局提交的算法

1 | |
1 | |
计算节点从存储节点获取到最新的元组版本(fresh_tuple),依据时间戳顺序依次对遍历事务
首先是 T1,由 rset 确定首先受影响的读操作(R2)
根据 dataflow graph 重新执行与它相关的写操作(W4)
接着根据时间戳的顺序重新执行 R7, W10,最终生成 batch.delta_wset,发送给存储节点;
计算节点和存储节点都可以根据 delta_wset 生成 final_wset,将本地缓存或数据项持久化
全局提交和快速路径优化的区别在于:
- 前者需要完成2PC的两个阶段,由计算节点对事务进行修复,修复后发往各个存储节点执行;
- 后者直接由存储节点对事务修复,执行并完成提交后,返回通知计算节点
4 Hackwrench 实现细节
Batch splitting
本地节点需要对自己的所有事务划分批次,将所有事务划分成多个非冲突的子批次。
方法:构建一个无向图,各个事务为图的顶点,如果两个事务之间有相同数据项的访问,这两个顶点之间将会有一条无向边进行连接;每个连通分量所包含的各个事务都是可能产生冲突的,它们将形成一个子批次,进入分层提交协议的本地提交阶段。
Fine-grained re-execution.
To mitigate the abort cost, we need a more efficient solution than aborting and retrying a batch of transactions. Our insight is that it is cheaper to repair the transactions batch by selectively re-executing operations affected by stale or invalid reads.
一个直观方法是根据事务的依赖图来进行,如果每一批次使用一个大的依赖图囊括所有的事务操作将导致构建和遍历复杂度过高。
论文中采用的方法:
由于同一个批次中的事务操作顺序是能按照时间戳顺序确定的,修复可以按照事务的顺序进行修复;
每个事务会生成一个静态的数据流图,Hackwrench可以根据数据流图修复事务;
对于读操作,计算节点会根据 fresh_tuple 重新读取,然后依据 dataflow graph 对所有与读操作有直接联系的写操作进行重新执行。
5 实验
BenchMark
- TPC-C
- FDB-Micro
FDB-Micro是一个kv benchmark,元组分布在多个不同的存储节点,包含 80% 的只读事务和 20% 的读写事务(select+update),参数d代表分布式事务的占比
TPC-C主要以 multi-wareHouse NewOrder 分布式事务的占比对比系统的吞吐量和延迟;
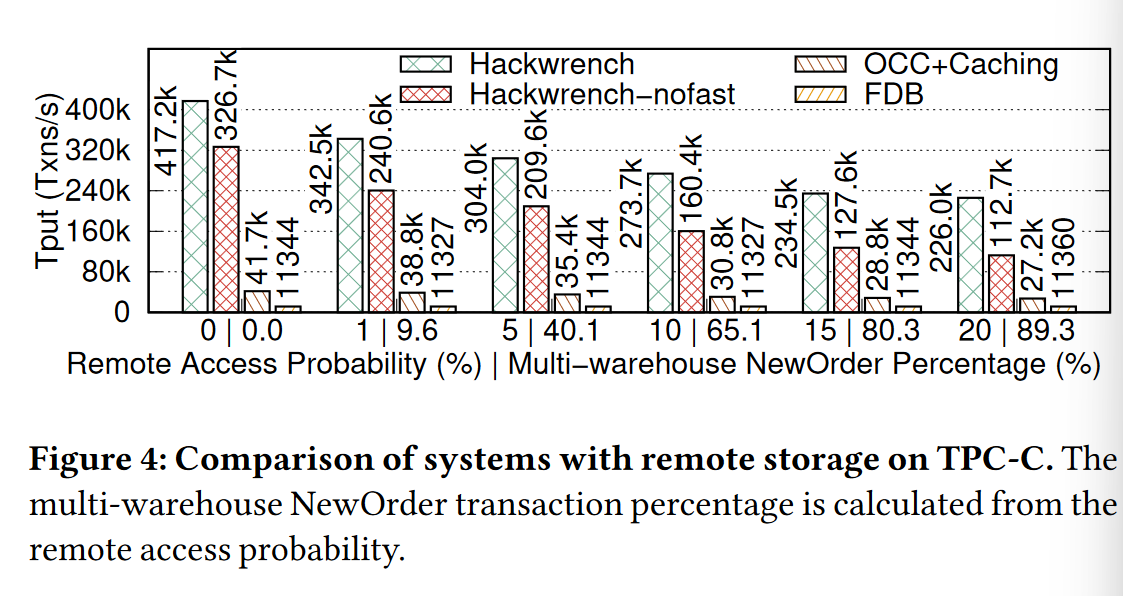
实验1:对比在分布式事务占比不同的情况下各个系统的性能比较
分析:Hackwrench吞吐量相比其他两个系统有将近10倍的提升,主要体现在
- 事务是批处理形式提交
- 在节点本地的事务并发过程中,允许读取本地已提交但全局未提交的数据
- Hackwrench 通过修复事务(部分操作重做),而不是abort整个事务得到了吞吐量的提升
Hackwrench 与 nofast 版本的对比,前者在处理 one-shot 事务的时候将事务的提交和修复权给到了存储节点,避免了多一次的2PC通信往返,使得吞吐量得到提升;
FDB性能表现较差的原因在于其计算节点并没有缓存数据,导致每次事务执行需要读取数据都得进行一次与存储节点的通信往返;但有意思的是,FDB在分布式事务占比数量不同的情况下仍然有一个稳定的吞吐,是因为FDB不使用缓存也就不会出现缓存陈旧而读取存储节点来增加通信次数;
实验2:对比分析几种系统的延迟
分析:
相比于 OCC+Caching 系统,当 batch size 增加时,Hackwrench 系统的延迟会增加,这是由于时间都花在了本地节点形成批次的场景上,若BS=1,单个事务执行完直接全局提交,并不需要考虑前面事务在队列中的阻塞;
(虽然BS增加会增加延迟,但它会减少节点之间的通信次数,进而提高吞吐量)
OCC 比 FDB 快的原因在于每次通信会更新多个tuple到本地缓存,下次执行时会减少通信次数,降低延迟
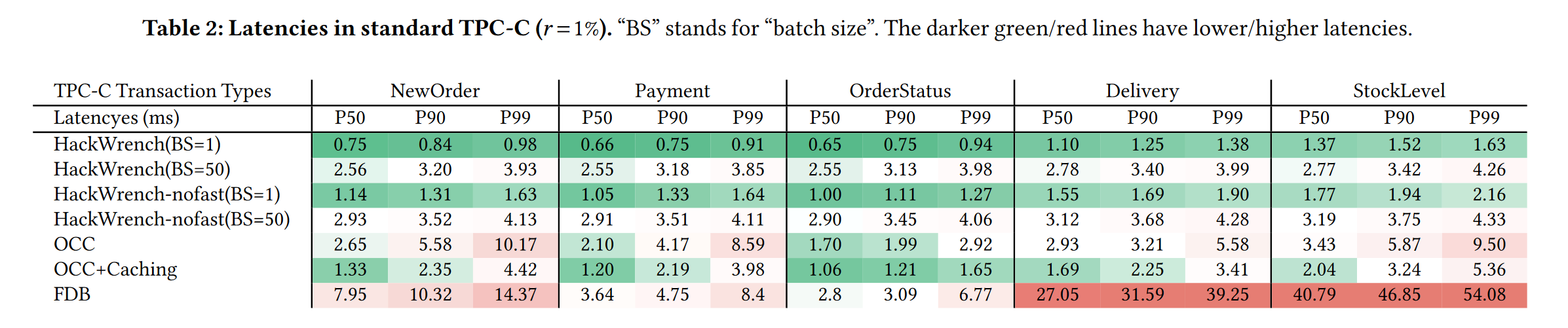
实验3:对比分析5种优化里面,哪些在OCC基础上的优化最大
r 代表 TPCC 中分布式事务 multi-warehouse NewOrder 的占比
caching 和 batching 都有一定的吞吐量提升;
+RU 指本地节点能读取本地已提交但全局未提交事务修改的数据,在低竞争条件下时(几乎没有分布式事务时,吞吐量特别高)
+Repair 指采用细粒度修复事务的方法,吞吐量提升明显;
+Fast 指在 one-shot 事务上直接让存储节点提交和修改,吞吐量提升显著;
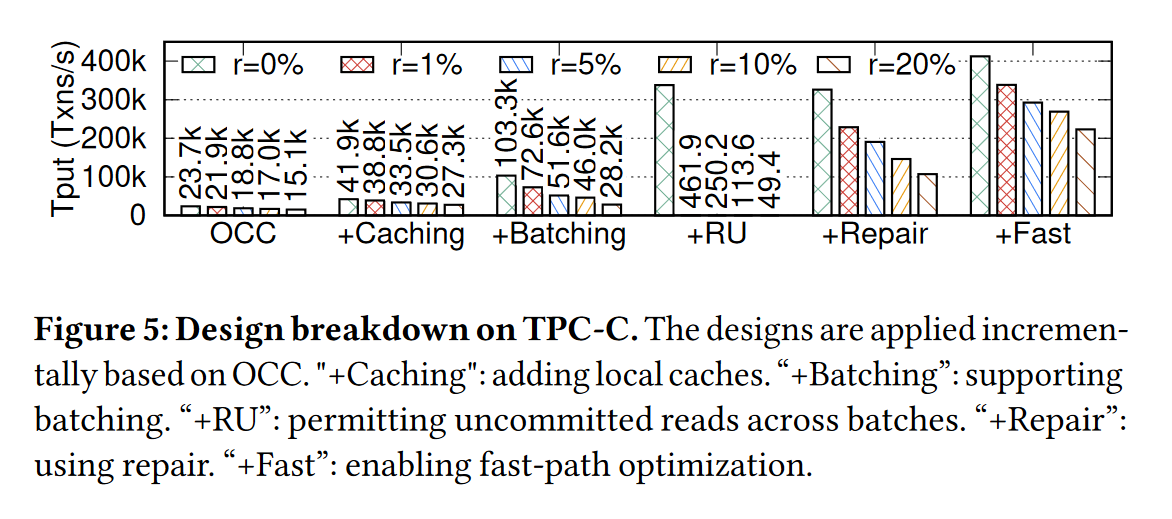
实验4:对比分析各个系统的CPU利用率
随着与远程节点访问的增加,网络通信开销的增加,吞吐量在减少
但 Hackwrench 仍然能够保持一个比较高的吞吐量;
右图是对比各个系统的CPU时间分布:
- COCO由于每个事务需要单独进行全局提交的验证,计算节点大部分时间处于阻塞的状态
- Calvin系统是规定每个事务在所有计算节点都需要进行提交,导致CPU大部分时间花在了多节点同步的过程
- Sundial 是不支持复制的,在10(a)中,当事务基本都是单点事务时,吞吐量非常高;但在右图中,与COCO一样,每个计算线程只允许每次验证单个事务,并且在事务重试前进行了sleep,因此CPU的利用程度不足
- 与上面三个相比,Hackwrench 充分利用了CPU,大部分时间花在了事务的执行,剩余时间大部分用在了全局提交阶段的 prepare 和 commit 阶段。
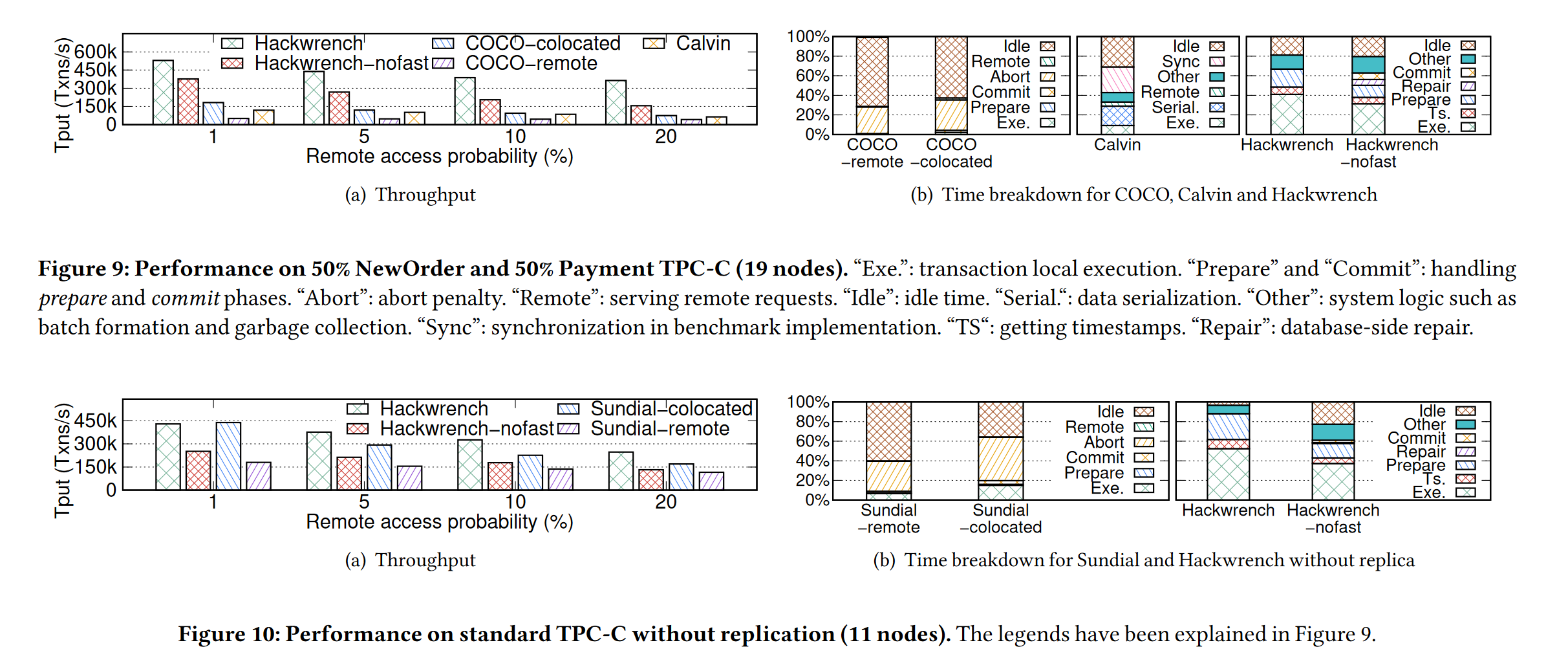
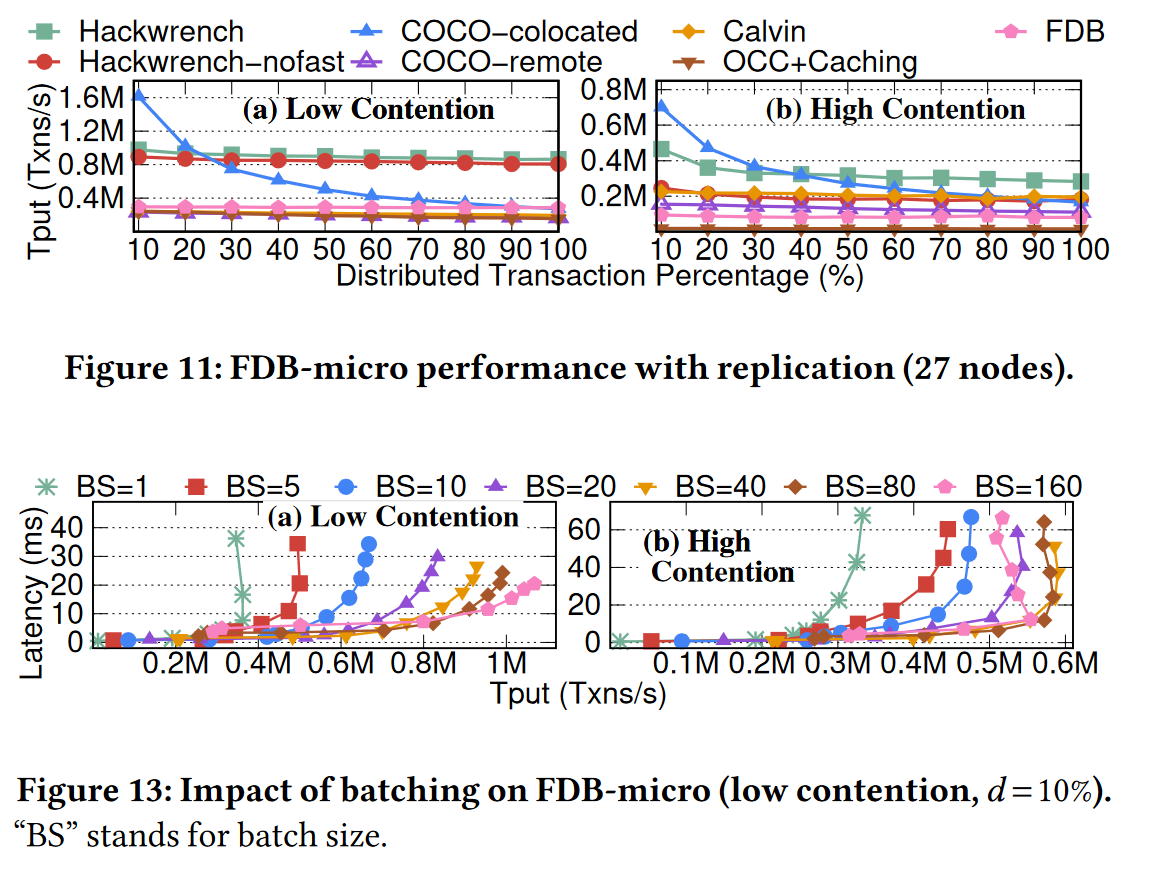
实验5 以 FDB-micro benchmark 为基准的在不同分布式事务占比系统的吞吐量
图11表明,COCO系统在分布式事务少的时候吞吐量表现优异,但分布式事务增加会导致吞吐量的下滑,而 Hackwrench 保持了较高的吞吐量;
并且在11(b)与11(a)的比较中,在高竞争场景下,Hackwrench 在 one-shot 事务的 Fast-path opt 优化在吞吐量上有显著的提升;
图13是说明 batch size 的不同对吞吐量和延迟的影响,吞吐量越大,延迟越高,是因为本地节点将事务成批的过程耗费了整体的时间;
同时,随着 batch size 的增加,由于引入了细粒度修复事务的策略,能让延迟增长地更加缓慢一点
6 分布式OLTP系统的两种分类
1、remote-storage system
存算分离,spanner,FoundationDB,事务中的所有读都需要与远程的存储节点通信;
2、co-located system
将事务的执行(计算)与 存储节点的工作线程 放在一起,可以最大限度减少网络通信开销;
但涉及到跨分区的操作,仍然需要与远程节点通信,来确保事务的正确执行。
代表的三个系统
- Calvin (SIGMOD 12)
在执行之前,为整批事务分配了总的顺序再进行执行和提交,并且避免了2PC的开销;
规定每个事务在所有计算节点都需要进行提交
与 Hackwrench 的对比:后者是在整批事务执行完成后,再为事务分配提交顺序;
- COCO (VLDB 21)
准备提交事务批时,对每个事务单独进行验证,再进行批量复制;
与 Hackwrench 的对比:后者由于使用细粒度重新执行,能够批量验证和批量复制
- Sundial (VLDB 18)
使用逻辑租约的方法进行缓存管理,以降低OCC验证失败的概率;
与 Hackwrench 的对比:后者允许OCC验证失败,但通过细粒度修复来保证性能