6.824-raft-笔记
Raft算法中服务器的三种角色
- Follower
- Candidate
- Leader
每台服务器需要维护的变量
每个节点的持久状态:
- currentTerm: 当前节点位于的最大的Term任期,初始化为0,单调递增
- log []Entry : 日志条目(每条日志条目包含命令和任期)
- votedFor: 可以理解为当前任期 支持的候选者 或 当前整个系统的leader
votedFor 一开始为 -1,以下情况将改变 votedFor 的值:
- 选举超时(相当于心跳超时),follower 转变为 candidate,votedFor = me 更改
- 收到 leader 的心跳,votedFor = leaderId 更改
- 收到任意 server 的 term > currentTerm,votedFor = candidateId 更改
- 竞选超时,votedFor = me 不变
- 成为 leader,votedFor = me 不变
每个节点的易失状态:
- commitIndex: 当前节点最高的被提交的日志的索引, 初始化为0并单调递增
- lastApplied: 当前节点最高的被应用于状态机的日志的索引, 初始化为0并单调递增
Leader 竞选成功后需要维护的变量:
1、nextIndex[n]: 下次与各个follower进行日志同步时,发送的日志起始序号
初始化为leader最后一个日志索引+1
即下回发送 [ nextIndex,leader_all ]
2、matchIndex[n]: 与各follower节点同步到的日志序号位置,init = 0
在日志复制环节:
为什么有了 nextIndex 还要有 matchIndex,matchIndex为什么不等于 nextIndex - 1?
由于领导者在同步follower日志的时候,需要考虑容错,即发生丢包等情况
- 如果follower更新成功:
matchIndex[ me ] = 最后一条日志 + 1 (防止客户端可能在并行发送)
matchIndex[ follower ] = 领导者已发送的最后一条日志
nextIndex[ follower ] = matchIndex[ follower ] + 1
- 如果follower更新失败:
nextIndex[ follower ] –,matchIndex不变
注意 nextIndex 不能小于0
比如:领导者:A B C D E,在某时刻,follower 有 A B F;
第一轮:nextIndex=6,matchIndex=0,leader发送空日志,
- 匹配失败 matchIndex = 0,nextIndex = 5
第二轮:leader 发送 [ E ],
- 匹配失败 matchIndex = 0,nextIndex = 4
第三轮:leader 发送日志 [ D E ],
- 匹配失败 matchIndex = 0,nextIndex = 3
第四轮:leader 发送日志 [ C D E ]
- 匹配失败 matchIndex = 0,nextIndex = 2
第五轮:leader 发送日志 [ B C D E ]
- 匹配成功,matchIndex = 2,follower 删除 F,添加后为 [ A B C D E ]
一般变量:
- role 处在的角色:领导者、跟随者、候选者
- electionTimeout:选举超时
- totalVotes:当节点为 candidate 时,收到的选票数
- timer 定时器,不同状态下的超时不一样(选举超时,竞选超时,心跳超时)
- heartBeatChannel chan bool 心跳包通道,用于follower状态下接收来自leader空的心跳包
- isLeaderChannel chan bool 一旦选上成为领导,通道里就有一个true,仅用于在make中的candidate分支判断
4、RPC 请求和响应
(1)领导者选举:RequestVote RPC
当节点成为 candidate 后,将调用所有其他节点的 RequestVote 函数
请求参数:
- term: 当前 candidate 节点的 term 值
- candidateId: 当前 candidate 节点的编号
- lastLogIndex: 当前 candidate 节点最后一个日志的下标(从1开始)
- lastLogTerm: 当前 candidate 节点最后一个日志的 term 值
返回值:
- term: 其他节点的当前任期, 如果比自己大,则需要更新 candidate 自己的 term,转化为跟随者
- voteGranted: 是否给该申请节点投票,true:给当前节点的选票 + 1
选举RPC如何保证安全性,为什么需要 lastLogIndex 等参数?
可能存在的不安全性:
一个follower在进入宕机后它的leader提交了若干日志条目,当follower重新上线后,leader宕机了,此时如果重新选举,在没有安全限制的情况下,这个follower可能当选为领导者,并且覆盖leader已提交的条目,导致每个状态机执行的序列不一致。
A:1 2 3,leader时候将123均复制到大多数节点,123均为committed
B:1 ,宕机 | 恢复 4
此时A宕机了,B又恢复了,如果B被当选了,将会覆盖掉23,正确的是应该由当前集群中日志最新的节点当选,这样能保证每个节点的状态机执行的日志序列相同
解决方法:
1、原领导者的日志达成 commit 的条件:超过半数的 follower 成功复制了该日志条目
2、候选者在投票给其他节点时,follower将自己最后一个日志的编号和任期号和传入的candidate的日志编号和任期号做比较,
- 如果与candidate相同或candidate更新一点,则允许给它投票
- 否则不变
(在集群中没有选出领导者时,客户端发送的指令将阻塞)
Raft 保证日志安全性的措施:Leader 在commit日志时,只能提交当前任期的日志
场景:(Corner Case)
A: 1 1 2 3
B: 1 1 2
C: 1 1 2 3 3 | 4
C在任期3是leader,1123都是已提交的,但在最后一个3提交之前宕机了,之后重新上线,超时重新选举,C由于最新在任期4又成为了leader,此时第二个命令3如何处理?
丢弃?还是将其改为任期4,然后复制给其他节点?
raft论文里的方法:每个领导者刚当选时,提交一个 no-op 无操作日志
一种可能实现的方法:
宕机后通过 readPersist() 方法读取获得 commitIndex,
log 直接截至到 commitIndex,丢掉后面未提交的之前任期的日志;
但这样客户端在超时后可能需要重新向集群发送被丢弃的日志(需要在客户端处理)
或者将所有commitIndex ~ leader_log_end 的所有日志的任期改为当前任期(能保证容错)
Corner Case 2
3个节点012,1一开始被选为leader,客户端传入第一条日志{100}
1维持着心跳,但1与0两个节点之间网络不顺,直到超时0号节点依然没能收到1的心跳
此时0超时后成为candidate,term+1,通过了2号节点的选票
这样一来,当网络正常后,1和0又能连接上了,此时0的任期比1大,会让1变更为follower
之后,假定网络一直顺畅,0一直是leader,则那条日志永远不会复制给除1以外的节点了
(网络分区)
解决方法:在RequestVote()
Raft 中的超时时间
超时时间:建议随机生成 150ms ~ 300ms,论文中提到的是 50ms~500ms
1、选举超时时间(Election Timeout)
每个 follower 维护一个随机的超时时间,在这个时间范围内,只要没有收到领导者的心跳,即可转变为候选者。包括:
第一次选举的超时时间
没收到领导者心跳包的心跳超时
2、竞选超时
当前节点状态为 candidate,在规定时间内没有获取到足够多的票数,则当前轮次的选举竞选失败,当前节点重新回到 candidate,对应状态机中的自环。
此时,需要重置超时时间、得到的票数重置为0
关注时间的设置,raft若要稳定工作,必须维持一个稳定的leader:
广播时间 < 选举超时 < 平均故障间隔时间
broadcastTime < electionTimeout < MTBF
广播时间:一个服务器并行发送 RPC 给其他服务器,接收,响应的平均时间;
由于选举超时 == 心跳超时,要想维持领导者稳定,心跳超时必须远大于广播时间
5.3 Leader 复制日志 / 发送心跳包
1、整体日志复制流程:
- 客户端发来的每条消息里面包含一条待执行的指令
- leader 会将指令追加到自己的 log,然后通过 AppendEntries RPC 并发复制给其他节点
- 复制成功后(commited),leader 将这条日志交给自己的状态机执行,然后将结果返回给客户端
- 如果 follower 挂掉了或很慢,或者发生了丢包,leader 会无限重试 AppendEntries 请求,直到所有 follower 最终都存储了所有的 log entries
2、提交的定义
Commited:leader 将它成功复制到大多数节点(大于n/2),这个 entry 就算提交了
3、Raft 日志的两个基本定理
- 如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们存储了相同的指令。
- 如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们之前的所有日志条目也全部相同。
在正常情况下,即每个任期的领导者均不发生宕机的情况下,所有 follower 的日志都是和领导者保持相同序列,即使 follower 宕机回来后也能正常从当前末尾依次复制缺失的日志。
4、日志不一致的场景
当领导者节点发生宕机,后面的未 commit 的日志将会在该领导者节点上形成冗余
比如下图 (c) 是任期6的领导者,前三个日志都持久化了,但最后一个未发送到其他节点,自己就宕机了
(框框里的数字代表每个日志创建时的任期)
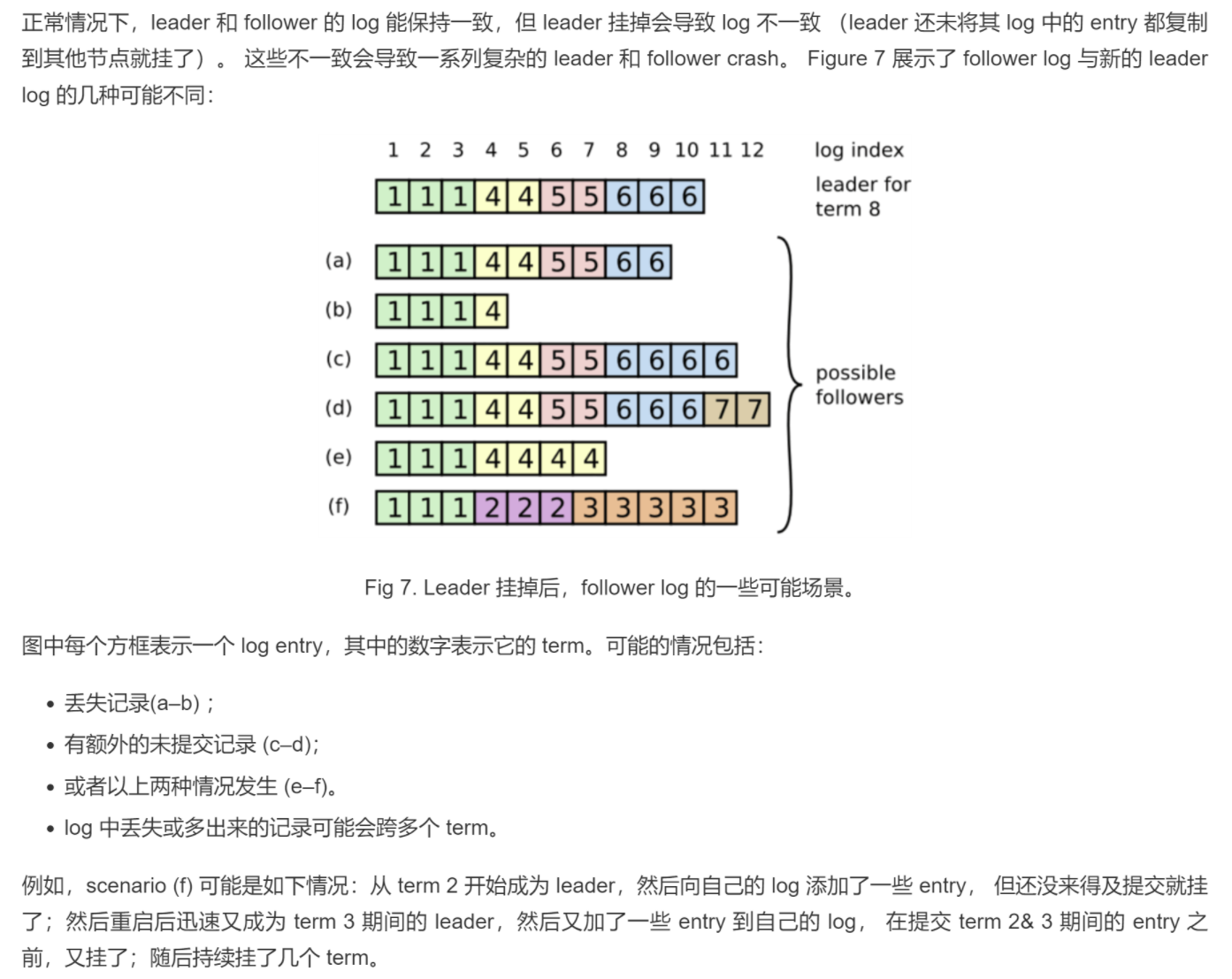
5、解决日志不一致的办法
(1)领导者需寻找 leader 和 follower 的最后一个完全相同的条目,该日志编号为 a
(2)删除 follower 那个条目之后的所有项 ( delete a+1 ~ all )
(3)leader 发送自己的日志给 follower (send a+1 ~ leader_last_log )
但如何将上述三个操作合并为一个 RPC 进行处理呢?
领导者针对每个 follower 维护一个 nextIndex,
当领导者刚获得权力的时候,初始化所有 nextIndex = 最后一条commit的日志编号 + 1
调用 RPC 第一次可能失败,此时更新 nextIndex = follower匹配的最后一条 + 1
间隔数ms,第二次调用RPC,发送日志 [ nextIndex, last_log ]
详细描述:
1、Leader节点维护的变量nextIndex[followerID]:其他各个节点下一个需要给到的日志
2、节点选举Leader成功后,首先将所有 nextIndex 初始化为 log 的下一个编号(图7的11)
3、发送 AppendEntries,对于 follower i, 根据下列日志匹配原则进行判断
日志匹配原则:如果两个日志条目包含的 index 和 term 完全相同,那从这个条目往前的所有条目也都是完全相同的。
比较请求参数中的上一个日志编号的任期 prevLogTerm 与 follower 节点中的对应日志编号的任期 log[ prevLogIndex ].Term
(其中prevLogTerm 等于 leader 中的 nextIndex[followerId] - 1,即当前最末尾的日志编号)
如果不一致,则 follower 直接拒绝请求,leader 收到拒绝后,将减小 nextIndex[followerId] 重试,直到有日志是两边匹配的;
当匹配成功后,follower 将会删除 index 之后的所有日志,并将 leader 中从这个 index 往后的所有日志复制到自己的 log 里面;
follower 需要注意的几点:
(1)如果 args.term < currentTerm,return false
(2)如果 prevLogTerm 与节点的 log[ prevLogIndex ].Term 不匹配,return false
(3)args.leaderCommit 用于更新节点的 commitIndex (在匹配完日志后)
如果存在日志条目的序号 N,且领导者的 log[N].term == currentTerm,在满足
- N > 节点的 commitIndex
- matchIndex[节点id] >= N
两个条件对大部分节点都成立时,设置领导者的 commitIndex = N
(4)如果 leader 的 commitIndex 大于 节点的 commitIndex,在更新了节点的日志后
跟随者节点的 rf.commitIndex = min( leaderCommit, len(rf.log) )
确保能跟 leader 一样保持正确的 commit
5、AppendEntries RPC 参数
请求参数:
- term: 当前leader节点的term值
- leaderId: 当前leader节点的编号
- prevLogIndex: 当前发送的日志的前面一个日志的索引 (nextIndex[节点编号] - 1) 索引是自增的
- prevLogTerm: 当前发送的日志的前面一个日志的term值 log[prevLogIndex].term
- entries[]: 需要各个节点存储的日志条目(用作心跳包时为空, 可能会出于效率发送超过一个日志条目)
- leaderCommit: 当前leader节点最高的被提交的日志的索引 (就是leader节点的commitIndex)
返回值:
- term: 接收日志节点的term值, 主要用来更新当前leader节点的term值
- success: 如果接收日志节点的log[]结构中prevLogIndex索引处含有日志并且该日志的term等于prevLogTerm则返回true, 否则返回false
figure 8 证明 + requestVote需要考虑最后一个索引的原因:
每个 candidate 必须在 RequestVote RPC 中携带自己本地日志的最新 (term, index),如果 follower 发现这个 candidate 的日志还没有自己的新,则拒绝投票给该 candidate。


疑问1:
在raft论文里面,提到了三个超时,一个是选举超时(follower转变为candidate),一个是心跳超时,一个竞选超时(就是规定时间内没有获取到足够多的票数,则当前 Leader 选举竞选失败)
但是这幅图里面candidate超时立刻发起一轮新的选举,会不会造成两个节点同时开始选举,同时发生超时这样的循环,我想的是超时后能不能先转换成follower,通过 election timeout 再转换成candidate
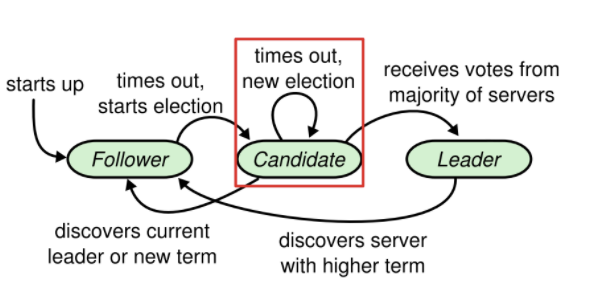
解决办法:用同一个定时器timer在不同状态下完成不一样的定时效果,比如:
- votedfor=-1且为follower时,定时的是选举超时
- votedfor不为-1且为follower时,定时的是心跳超时
- 角色为candidate时,定时的是竞选超时
每当节点的状态发生转变时,timer重新生成一个超时时间,以下几种状态的转变:
- 转变为 candidate 时,立刻重置超时时间
- 转变为 follower 时,立刻重置超时时间
- 当前角色为 follower,但 votedFor 参数改变时,立刻重置超时时间
疑问2:
节点重新连接后,从哪里开始执行代码?
1、开启新节点的执行顺序:
make_config() -> cfg.start1() 分配一个全新的raft节点 -> Make() 创建一个协程判断自己的状态,主程序返回
这里当一个节点 disconnected:在Make里面的协程依旧是执行的,但与其他各个节点无法通信
因此,reconnect 的含义是,Make里面的协程重新可以与其他节点进行交流,从协程的首部继续执行
疑问3:当绝大部分机器挂了,最多只能收到的选票数量小于(n/2+1),怎么办?leader 没法选出来
疑问4:节点重新连接后,若原先就是leader,接下来如何操作?
- 是接着发送心跳包,并在接收可能已成为 leader 的节点比较 Term 大小,进而选择继续当领导者或转变为跟随者(正确)
- 还是直接变成 follower,等待超时时间结束,开启新的一轮选举?(错误)
疑问5:一直过不了2A的根本原因:
3个节点,当他们都成为 candidate 后,此时 votedfor 都只为自己,造成投票分裂,节点会在竞选超时后,再等待一定时间?,重新转换为 candidate
结果就是所有节点几乎一直都是 candidate,直到 5s 后选举失败
解决办法:只能根据谁的 term 大,另外的在比较完 currentTerm 后转变为 follower
同时,随机数种子必须是time.Now().UnixNano(),否则时间靠太近选不出来
疑问6:Make中的 applyCh chan ApplyMsg 有什么作用?
这里是对节点日志提交的一种假定,每个节点都有一个 applych 的通道,当某项日志实现commited后,就会将这条日志打包成 ApplyMsg 发送到通道中,在测试文件中,goRoutine会遍历每个节点的这个通道,若一个日志已经被大多数节点commited,则视为提交成功的测试判断依据
疑问7:正确的 commit、apply 顺序?(并发条件下的正确顺序)
1、leader 收到指令,存到 log 数组,用n个并发协程向其他节点复制这条日志
2、这 n 个协程中,当有 n/2+1 个协程返回成功时,说明已经将日志复制到大多数节点上了
此时,
- n/2+1 个节点:LeaderCommit 仍然在0,但日志长度和 leader 相同;
- leader:LeaderCommit 更新为1,将这条日志 apply 到状态机上;
- 其余节点:无变化
3、剩下协程执行完 RPC 准备返回,此时:
- n/2+1 个节点:无变化,保持 LeaderCommit 仍然在0
- 其余节点:LeaderCommit 更新为1,将这条日志 apply 到状态机上;
4、下一轮 leader 进行 AppendEntries RPC 时,或发送心跳包时
- n/2+1 个节点:LeaderCommit 更新为1,将这条日志 apply 到状态机上;
疑问8:2B最简单的过不了的最大可能性:
测试文件要求 raft 所有的索引,比如 nextIndex 必须从1开始
因此 log[] 一般都需要 index - 1
为什么 $cfg.rafts[i].log$ 与 $cfg.logs[i]$ 开始序列不同?
前者从0开始(用户编写),后者从1开始(按照论文)
前者在start的append中加入到当前节点的日志 raft[i].log,但这个日志实际上并没有被状态机执行,并不是commited,所以后者此时并没保存这条日志;
后者发生在 ApplyLogToStateMachine,在节点认为该日志已经commited情况下,将这条日志放入了 msg,
而这个msg通过 applych 通道传给 config.go中的协程 applier(i, applyCh),这个协程将通道里面的每个传进来的日志赋值给 cfg.logs[i]
config.go: 152
解决方案:
将日志编号和存放的索引位置解耦,论文中也是 Index 从1开始
1 | |
疑问9:客户端刚submit后领导者宕机的情景
场景:假设A成为了leader,A在任期1内收到客户端陆续submit的命令1,2,3,在某个时刻,A成功复制命令1,2到了大多数节点,1,2视为已提交,但突然A宕机了,此时集群重新选出C来担任领导者,那客户端原本提交的命令3去哪了,如何解决?
这种情况需要客户端使用请求等待的容错策略,由于选主和日志复制的耗时在毫秒级,因此客户端实际上可以等待直到当前submit的请求被commit,并应用于状态机,可以确保消息不会因选主而丢失。
集群成员变更
为了让 raft 更有弹性,需要对外提供集群更改的接口/RPC,管理员可以随时拓展或删除集群中的机器:

在安全性方面,如果同时添加若干个机器,将可能导致问题:
下面的例子里,集群从3个服务器增长到5个服务器
在某个时刻点,两个不同的领导者可以在同一个任期内被选举出来;
一个拥有旧集群的多数票,一个拥有新集群的多数票
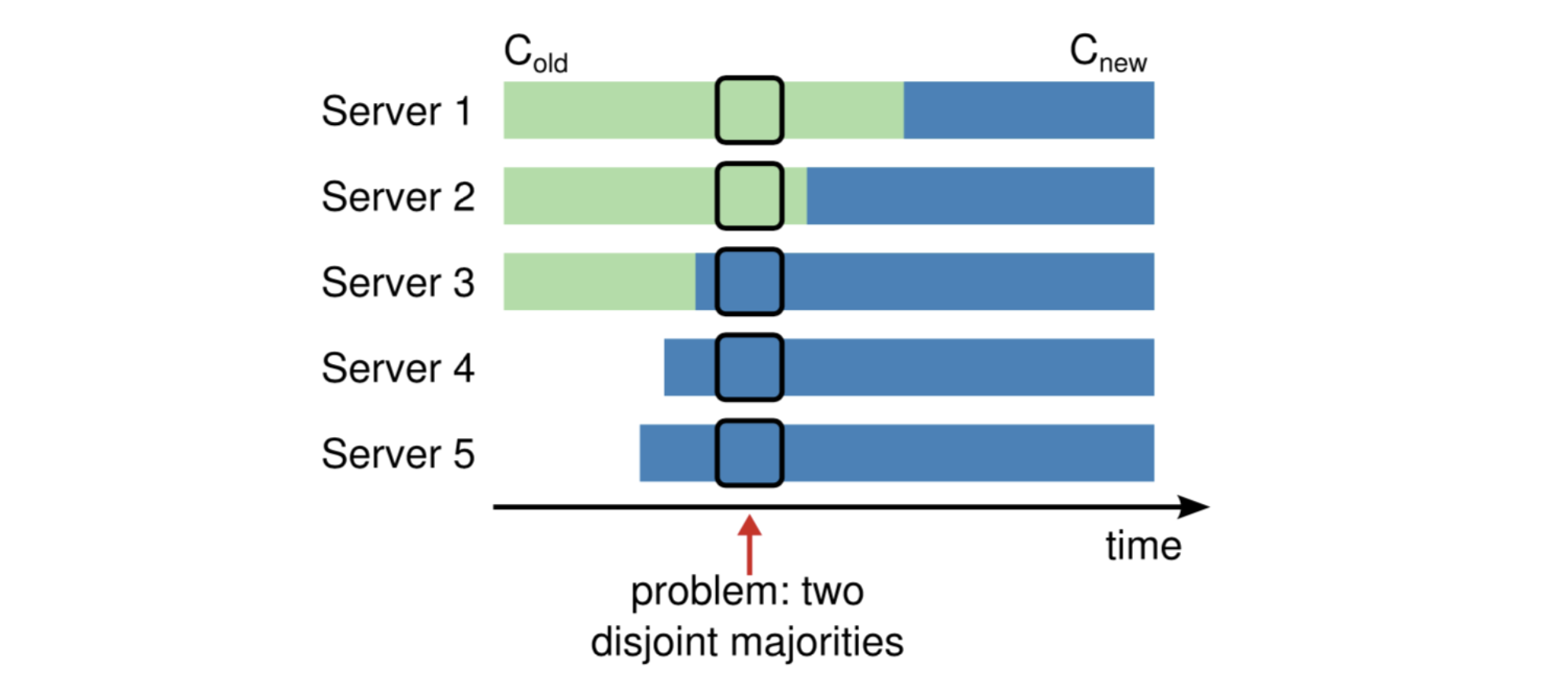
因此,Raft 限制了允许的更改类型:一次只能从集群中添加或删除一个服务器。
golang 定时器的使用
1 | |
Duration 类型
Duration 类型用于表示两个时刻 ( Time ) 之间经过的时间,以 纳秒 ( ns ) 为单位。
1 | |
channel
在并发条件下,函数与函数之间交换数据的两种方式:
- 用锁实现的共享内存
- 类似通信的方式用通道传递信息
go语言的并发模型是CSP,用通信传递信息(Communicating Sequential Processes)
channel 是可以让一个 go routine 发送特定值到另一个 go routine 的通信机制
1 | |
无缓冲通道与有缓冲通道
1 | |
无缓冲通道上:发送操作会阻塞,直到另一个goroutine在该通道上执行接收操作,这时值才能发送成功,两个goroutine将继续执行。相反,如果接收操作先执行,接收方的goroutine将阻塞,直到另一个goroutine在该通道上发送一个值
单向通道
只能往这个 channel 中写入数据,或者只能从这个 channel 读取数据
单向通道的定义一般用在形参里,防止一些逻辑上的错误
1 | |
通道的关闭(只在发送端关)
close() 管道的意义:通过管道发送有限的数据时,可以通过close告知管道另一边的协程停止等待,数据已全部发送完毕。
上例第5行,发送端在发完所有需要发送的数据后,执行关闭通道;
关闭通道:表示发送端不再向通道里发送数据,但如果通道里还有数据,接收方仍会把数据接收完毕。
golang 中的 select 机制
1、select 的特点:每个case都必须是一个通信
2、不同于C++,go中每个case不需要break,它不会顺着下去执行
3、关于 default
两种写法:
1 | |
3、go 中的 case 语法
无论是 switch 还是 select,只执行 case i 里面的内容,不需要 break
如果要顺下去执行多个 case,使用 fallthrough 关键字
复制状态机的两个部分:
- 共识算法将主节点日志复制到其他所有节点,若在某一个节点中,如果已正确复制了日志,即命令和它的顺序,则视为已提交:commited
- 已 commit 的服务器将使用状态机执行这些命令
关于拜占庭故障:
拜占庭故障:故障节点可能存在各种形式的错误,如传递错误信息,完全违反系统规则,可能由恶意攻击,硬件故障导致;
9个将军率领的部队在各个山头,各个之间通讯只能由信使传达;
每个将军须向其余所有将军传达自己想要 进攻 或者 撤退,
当进攻或撤退票数超过一半时,所有人将达成统一意见,开始执行任务。
假设8个忠诚将军,1个叛徒。其中4个忠诚将军选择进攻,另外4个忠诚将军选择撤退;
但此时,叛徒给4个选进攻的将军传达进攻,给4个选撤退的将军传达撤退;
4个选进攻的将军获得5个进攻票数,发动进攻,同理另外4个撤退;
导致了队伍的最终一致性发生了破坏。
拜占庭故障的解决方案:数字签名密码学、PBFT
Raft 并不保证拜占庭容错,但可保证除了拜占庭条件下的其他错误,比如 网络延迟、分区、数据包丢失、数据包重复等异常。
结论1:Raft 可以容忍小于等于一半节点出现故障,系统仍能正常对外服务
比如5台服务器,任意两个发生了故障,系统仍能正常运行,更多故障只能重启。
lab2A

TestCount2B 测试点:(需要优化RPC次数)
要测RPC的次数:比如初始选举一个leader的RPC<30
TestBackUp2B
5个节点的集群,首先选出节点0成为 leader,发送日志 {1, 1, 100},
所有成员均复制并已提交
此时,断连 2,3,4节点,客户端向集群添加了50条日志,节点0和1复制完成后但由于复制成功的节点数量小于大多数节点,commitIndex 依然等于 1
此时,断连0,1节点,重连2,3,4节点,集群选出了2号节点作为新的 leader;
客户端向集群又新添加了50条日志,并等待三个节点将所有日志均提交,
2,3,4节点的 commitIndex = 51
此时,断连3号节点,客户端向集群又新添加了50条日志,但集群内只剩两个节点,无法达成多数节点复制成功,这50条日志并没有提交;
一段时间后,2,4节点失去连接,0,1,3节点重新连接,集群此时剩下了3个能互相连接的节点,3号节点当选为 leader,将已提交的全部更新到0,1节点,此后客户端向集群又新添加了50条日志,这些日志都被提交;
0,1,3节点的 commitIndex = 101
又过来一段时间后,所有节点都能够连接,2,4节点成为follower,将0,1,3节点的所有已提交的更新到自己的日志上;
最后,节点0依然是leader,客户端提交最后1条日志
所有节点的 commitIndex = 102,结束
AppendEntries RPC 优化:
from MIT6.824 Lecture 7
当网络分区造成的影响太长时,Leader 需要与刚恢复的 follower 节点进行日志同步,如果每发一个 RPC 递减一次 nextIndex,则同步一个 follower 最大需要发送 len(rf.log) 次RPC;
优化目标:减少 RPC 次数,并且尽可能快达到日志同步
1 | |
上面的三个参数仅用于匹配失败的情况
对比的两个条目:follower 在 prevLogIndex 的日志的索引和任期与 leader 传进来的比较
XTerm:
- 检查 follower 在 prevLogIndex 的任期号和 leader 传进来的 prevLogTerm 不同, 将自己的任期号放入 XTerm;
- 若 follower 在这个位置上没有日志条目,XTerm = -1,leader 将会根据 XLen 决定下一个 nextIndex;
XIndex:返回任期号为 XTerm 的第一个日志索引的编号;
XLen:
- 如果 follower 在这个位置上有日志条目,返回任期号为 XTerm 的日志的数量
- 没有日志条目,返回空白日志的数量:preLogIndex - len(rf.log),leader 将会回退到 nextIndex - BlankLogNum
这种方法相当于一个一个 Term 进行同步
分别可以用下列3种情景分类讨论:
1 | |
继续优化,为了能尽快日志同步,当匹配不上时,不必再等待心跳超时,直接发送下一个 AppendEntries RPC

lab2D Log compaction
1、日志压缩的原因和本质:
当日志的数量太多,会造成的影响:
- 空间占用过高
- 状态机完整执行一次时间过长,且会存在很多过时的日志
- AppendEntries RPC 让 follower 跟上 leader 的时间也会变长
每当进行一次日志压缩后,将会剔除过时的日志,比如图12中的 x=3 将会被 x=0 取代
日志压缩最简单高效的方法:Snapshotting 日志快照
2、日志快照需维护三个变量:
- 上一次快照的最后一个日志的索引:lastIncludedIndex
- 上一次快照的最后一个日志的任期:lastIncludedTerm
- 压缩后状态机保留的日志:State
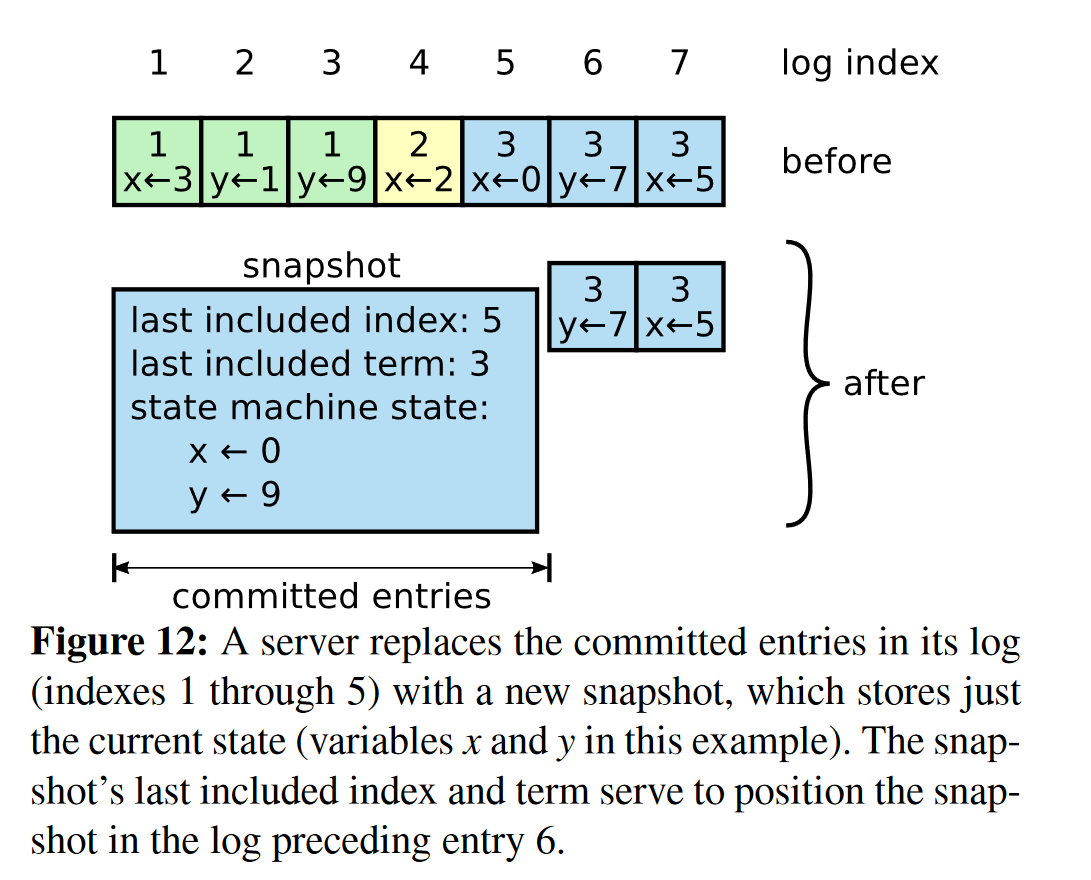
每个节点独立进行快照,lab里是每当节点的日志数量达到某个阈值时,进行一次快照;
为了保证快照的最终一致性,leader 需要周期性发送快照 RPC 到其他节点,当跟随者存在与快照中的日志不一致时,删除自己原先的所有日志,并用传入的快照替代;
3、要点分析
为了维护快照的状态,需要对 raft 结构体新增两个持久化的变量
- 上一次快照的最后一个日志的索引:lastIncludedIndex
- 上一次快照的最后一个日志的任期:lastIncludedTerm
这能够确保:当前准备进行的快照不是过时的,不会重复多次同一个快照
4、实现思路与分析
1、Snapshot()
当日志数量达到阈值时,测试文件将当前的 commitIndex 和 apply 到状态机的所有日志序列化成二进制编码,作为形参传入 snapshot()
1 | |
注意:
cfg.log:保存所有的 log
rf.log:保存压缩后的 log