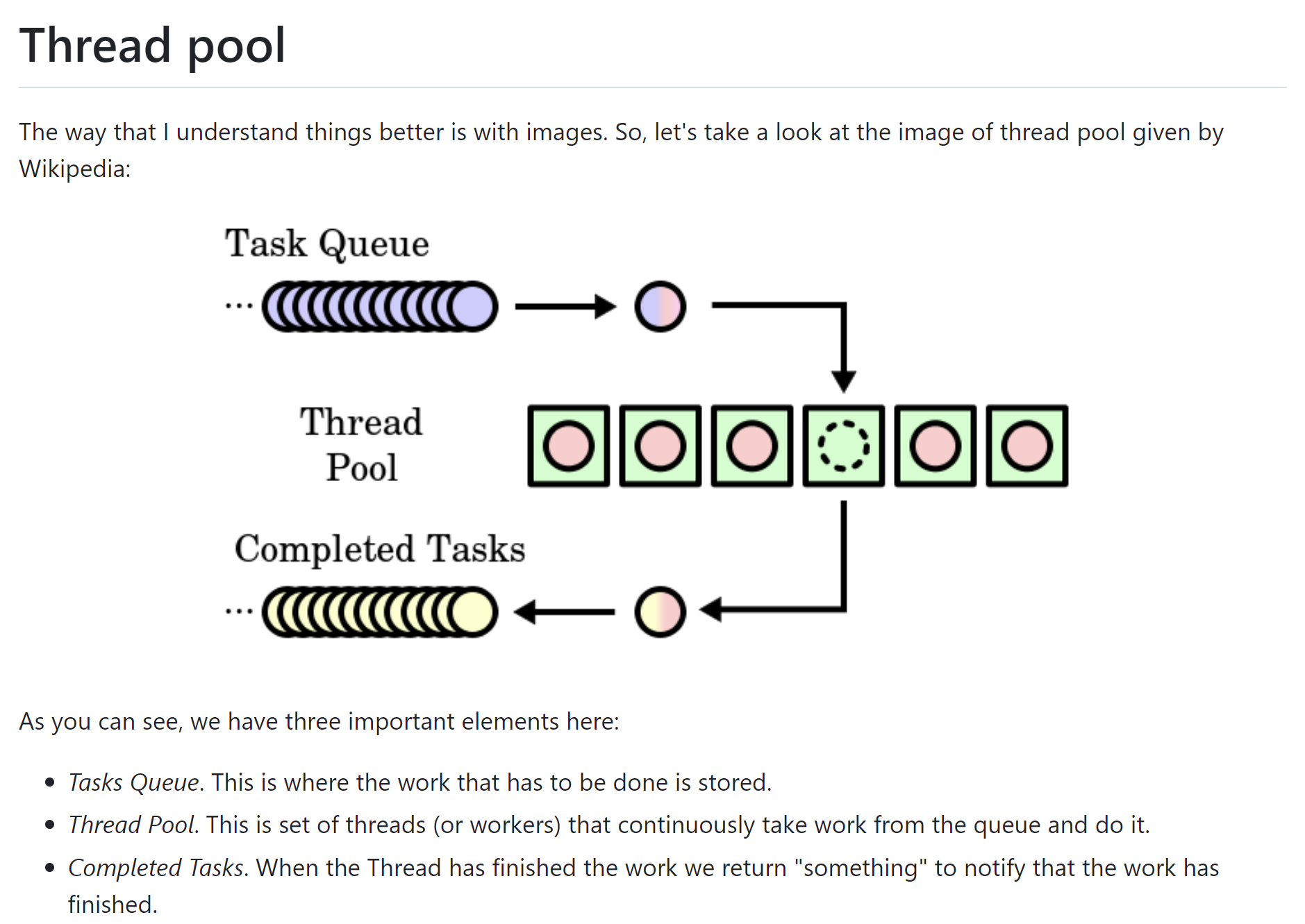
1. 线程池的基本原理和组件 线程池的定义:A thread pool maintains multiple threads waiting for tasks to be allocated for concurrent execution by the supervising program. Client can send “work” to the pool and somehow this work gets done without blocking the main thread. It’s efficient because threads are not initialized each time we want the work to be done. Threads are initialized once and remain inactive until some work has to be done.
三个基本要点:
一个高质量的C实现线程池:https://github.com/Pithikos/C-Thread-Pool
1.1 线程池需要向外提供的必要接口 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 threadpool thpool_init (int num_threads) ;int thpool_add_work (threadpool, void (*function_p)(void *), void * arg_p) void thpool_wait (threadpool) void thpool_pause (threadpool) void thpool_resume (threadpool) void thpool_destroy (threadpool) int thpool_num_threads_working (threadpool)
1.2 用到的数据结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 typedef struct job {struct job * prev;void (*function)(void * arg);void * arg; typedef struct jobqueue {pthread_mutex_t rwmutex; int len;typedef struct thread {int id; pthread_t pthread; struct thpool_ * thpool_p; typedef struct thpool_ {volatile int num_threads_alive; volatile int num_threads_working;pthread_mutex_t thcount_lock; pthread_cond_t threads_all_idle;
1.3 重要接口的内部实现 线程池部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 struct thpool_ * thpool_init (int num_threads){int thpool_add_work (thpool_* thpool_p, void (*function_p)(void *), void * arg_p) void thpool_wait (thpool_* thpool_p)
线程部分:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 static int thread_init (...) pthread_create (.., .., do_task, args);pthread_detach (..)static void * do_task (struct thread* thread_p) and let num_threads_alive++, unlockand let num_threads_runnning++, unlockjobqueue_pull ();func (args);and let num_threads_runnning--, unlockpthread_cond_signal (&thpool_p->threads_all_idle);and let num_threads_alive--, unlock
2. Oceanbase创建线程池并启动任务 1. 使用线程组创建函数注册一个线程池 线程池注册函数:TG_DEF(id, name, type, args…)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #define TG_DEF(id, name, type, args...) \ lib::create_funcs_[lib::TGDefIDs::id] = []() { \ auto ret = OB_NEW(TG_##type, SET_USE_500("tg" ), args); \ #name, TGType::type}; \ return ret; \#include "share/ob_thread_define.h" #undef TG_DEF enum class TGType TG_DEF (ParallelDDLPool, ParallelDDLPool, QUEUE_THREAD, 16 , 2000 )
为每个注册了的线程池赋予一个系统tg_id: lib::TGDefIDs::{id}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 namespace lib {namespace TGDefIDs {enum OBTGDefIDEnum 1 ,#define TG_DEF(id, ...) id, #include "share/ob_thread_define.h" #undef TG_DEF
2. 创建线程池类(基于 TGRunnable 或 TGTaskHandler 接口)
TGRunnable :适合处理无参数允许的任务,比如开启一个定时器等;
纯虚函数:virtual void run1() = 0;
TGTaskHandler :适合处理任何任务
纯虚函数:virtual void handle(void *task) = 0;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class ObParallelDDLOperator : public lib::TGTaskHandler {public :ObParallelDDLOperator ();ObParallelDDLOperator ();public :static int init () virtual void handle (void *task) override static int push_task (void *task) void stop () void wait () static void destroy () static ObParallelDDLOperator &get_instance () return parallel_ddl_; static inline ObArenaAllocator &get_allocator () return parallel_ddl_.allocator_; private :int tg_id_;bool is_inited_;static ObParallelDDLOperator parallel_ddl_;
2.1 线程池的初始化 1、根据已注册线程池的id,生成系统 tg_id,同时映射上 <tg_id,tg_queue_thread*>
2、将已实现的基于 TGTaskHandler 的 parallel_ddl_ 交给线程池,并调用 tg_queue_thread->start();
3、为方便后面调试线程数量,将线程数解耦放入 global context,可在配置文件中自定义。
1 2 3 4 5 6 int ObParallelDDLOperator::init () TG_CREATE (lib::TGDefIDs::ParallelDDLPool, parallel_ddl_.tg_id_);TG_SET_HANDLER_AND_START (parallel_ddl_.tg_id_, parallel_ddl_);TG_SET_THREAD_CNT (parallel_ddl_.tg_id_, GCTX.parallel_ddl_thread_num_);
2.2 线程池的任务队列接口 1 2 3 4 int ObParallelDDLOperator::push_task (void *task) TG_PUSH_TASK (parallel_ddl_.tg_id_, task);
2.3 每个线程完成任务的接口 具体的任务工作可由task对应类型的实现类的 do_task() 接口完成
1 2 3 4 5 6 7 8 9 void ObParallelDDLOperator::handle (void *task) static_cast <ObIDDLOperatorTask*>(task);if (xxx == ddl_task->get_type ()) {auto *trans_task = static_cast <ObTransEndDDLOperatorTask*>(ddl_task);do_task ();free (ddl_task);
3. 定义 Task 基类,实现各类型 Task 需要完成操作的接口 ob决赛中有这样一个小情景:在创建系统租户的过程中,需要完成 1650 张系统表的创建,
在原本的实现中采用的是一张一张表的创建,效率非常低,因此我们的思路是通过创建若干线程建表,
在实际的实现过程中,我们发现每张表都在使用事务进行创建,而事务创建和销毁也有开销;
因此,我们最终的方案是通过 batch create 来实现,每个 batch 由一个事务构成。
1 2 3 4 5 class ObIDDLOperatorTask {public :virtual ObDDLOperatorTaskType get_type () 0 ;
3.1 实现类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class ObCreateTableBatchDDLOperatorTask : public ObDDLOperatorTask {public :ObCreateTableBatchDDLOperatorTask (ObDDLService *ddl_service, uint64_t tenant_id, CallbackFunc callback, ObIArray<ObTableSchema> &schemas, int64_t begin, int64_t end);virtual ~ObCreateTableBatchDDLOperatorTask () override ;virtual int do_task () override virtual int do_task (ObDDLSQLTransaction *trans) override virtual ObDDLOperatorTaskType get_type () override private :int64_t begin_;int64_t end_;
构造函数:将任务所需的所有参数传入
回调函数:在这里调用的是下面的主线程原子操作:ObBootstrap ::inc_finish_ddl_task_cnt(),目的是每创建一个任务,主线程记录的任务数量 + 1,最后主线程只需通过返回的 get_finish_ddl_task_cnt() 来判断是否继续进行下去。
话说,这里其实可以使用条件变量来实现,不用这么麻烦(之后有时间再说)
do_task():综合各个参数,创建事务,执行建表指令
3.2 在服务逻辑中构造任务队列,使用线程池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 get_instance ();for (int64_t i = 0 ; i < batch_count; ++i) {int64_t left = i * batch_size;int64_t right = left + batch_size - 1 ; if (right >= table_schemas.count ()) {count ()-1 ;new ObCreateTableBatchDDLOperatorTask (&ddl_service, OB_SYS_TENANT_ID, &ObBootstrap::inc_finish_ddl_task_cnt, table_schemas, left, right + 1 );push_task (task);inc_start_ddl_task_cnt ();
使用原子操作等待所有任务的执行完毕,主线程才将继续
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 const int64_t start_time = ObTimeUtility::current_time ();while (OB_SUCC (ret) && ObBootstrap::get_finish_ddl_task_cnt () < ObBootstrap::get_start_ddl_task_cnt ()) {if (ObTimeUtility::current_time () - start_time > WAIT_CREATE_SCHEMAS_TIMEOUT_US) {break ;int64_t ObBootstrap::finish_ddl_task_cnt = 0 ;void ObBootstrap::inc_finish_ddl_task_cnt () ATOMIC_INC (&finish_ddl_task_cnt);int64_t ObBootstrap::get_finish_ddl_task_cnt () return ATOMIC_LOAD (&finish_ddl_task_cnt);
3. oceanbase线程池的实现原理 在前面的例子里, 以 tg_queue_thread 为例,从上层向底层探索:
上层的线程池类型实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class ITG {virtual int thread_cnt () 0 ;virtual int set_thread_cnt (int64_t ) 0 ;virtual int start () 0 ;virtual void stop () 0 ;virtual void wait () 0 ;virtual int push_task (void *task) virtual int set_handler (TGTaskHandler &handler) virtual int wait_task (const common::ObTimerTask &task) class TG_QUEUE_THREAD : public ITGpublic :TG_QUEUE_THREAD (ThreadCountPair pair, const int64_t task_num_limit);TG_QUEUE_THREAD () { destroy (); }int thread_cnt () override return (int )thread_num_; }int set_handler (TGTaskHandler &handler) {int ret = common::OB_SUCCESS;uint64_t tenant_id = get_tenant_id ();if (qth_ != nullptr ) {else {new (buf_) MySimpleThreadPool ();set_run_wrapper (tg_helper_);init (thread_num_, task_num_limit_, attr_.name_, tenant_id);return ret;int start () override {int ret = common::OB_SUCCESS;return ret;void wait () override {if (qth_ != nullptr ) {wait ();destroy ();int push_task (void *task) override {int ret = common::OB_SUCCESS;if (OB_ISNULL (qth_)) {else {push (task);return ret;private :char buf_[sizeof (MySimpleThreadPool)];nullptr ; int64_t thread_num_;int64_t task_num_limit_;
继续往下分析,ObSimpleThreadPool 是整个ob线程池实现模型的核心环节
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int ObSimpleThreadPool::init (...) init (task_num_limit, name, tenant_id);set_thread_count (thread_num);start ();void ObSimpleThreadPool::run1 ()
继续往下,分析线程池中线程的调度:
每个线程其实封装了worker,在当前线程的生命周期内,可以通过线程本地存储TLS获取到这个worker对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 int Threads::start () void Threads::run (int64_t idx) ObTLTaGuard ta_guard (GET_TENANT_ID() ?:OB_SERVER_TENANT_ID) ;static_cast <uint64_t >(idx);set_worker_to_thread_local (&worker);run1 ();
最底层线程的实现,本质就是调用 POSIX 中关于 pthread 的各类接口,并做一定的封装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int Thread::start () pthread_create (&pth_, &attr, __th_start, this );ATOMIC_FAA (&total_thread_count_, -1 );void Thread::dump_pth () void Thread::wait () pthread_join (pth_, nullptr );void * Thread::__th_start(void *arg) {
4. 复习: 4.1 条件变量 condition variable 作用:条件变量通过将等待线程挂起,直到条件满足主线程才继续,而不是通过一直循环检查条件,从而可以有效避免忙等,节省 CPU 资源。
1、多线程中用于线程间同步与通信的一种机制;
2、允许一个线程A休眠,直到等待另一个线程B满足特定条件时,A才再继续执行。
3、在不用条件变量时,线程A等待线程B满足一个条件C时,若C迟迟不能满足,A将一直使用CPU资源进行轮询,直到看到满足条件C时,不再轮询,A继续执行:这导致空耗CPU资源。
4.2 信号量 1 2 3 4 5 6 typedef struct bsem {pthread_mutex_t mutex;pthread_cond_t cond;int v;
基本操作:
1 2 3 4 5 6 7 8 9 10 static void bsem_init (struct bsem *bsem_p, int value) static void bsem_reset (struct bsem *bsem_p) static void bsem_post (struct bsem *bsem_p) static void bsem_post_all (struct bsem *bsem_p) static void bsem_wait (struct bsem *bsem_p)
Reference:
[1] https://github.com/mtrebi/thread-pool
[2] https://github.com/Pithikos/C-Thread-Pool
[3] https://open.oceanbase.com/train?questionId=600006